
A simple React and Redux Architecture
Posted on:
There are a lot of different ways to have a system built around React and Redux. The freedom is mainly because both frameworks are not opinionated on how developers leverage them. In this article, I’ll present a simple architecture that uses React and Redux. The idea is to not complicate the lifecycle by avoiding an excess of third-party libraries and instead focus on some core ones.
UI Components
The premise of having a simple code starts with having simple UI elements. Simplicity follows the React philosophy of having small and simple components. It makes code reading easier for developers who need to change it, makes writing unit tests faster, as well as reduces the side-effects that occur when modifying a piece of code. Most of the components won’t have a state at all. By most, I mean more than 95%.
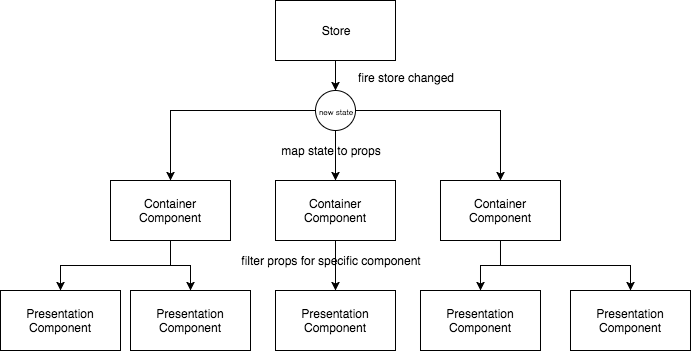
Most of the stateless components will be presentation components. These do no connect to Redux – they get their data from their properties and display it. When needing to take action, they dispatch using the properties as well. There are multiple reasons for this, the main reason being reusability. You can reuse these components regardless of the lifecycle. They are not tied to Redux or any other framework you may migrate to in the future. The second reason is simplicity. It is simpler not to be dependent on the store for testing.
The second type of component is the container component. These components are the ones that are listening to the Redux’s store. Page component and heavy control like grids may be connected to the store. However, all controls within the pages or grids shouldn’t.
React-Redux is the main library used to glue React components to Redux, and it is perfect to use for container components, but having too many of such components breaks the React hierarchical flow. That’s right; if every component hooks to the store, any change to the store will notify every component instead of just a few select ones that can then distribute the changes down. The flow is more predictable if it goes top to bottom than every component getting notified. That being said, a balance is required as well. Otherwise, too many components will have a huge properties list or have a very high-level property which makes them access too many values, thus confusing developers what they should access.
Loading Page
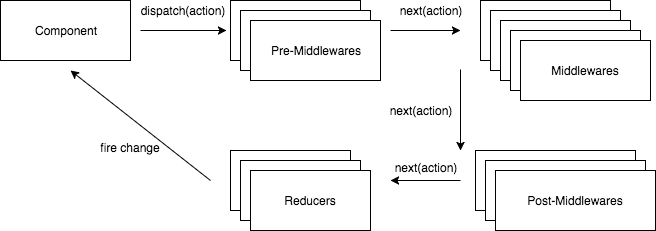
Everything starts when a page is loaded. React-Router is a key third-party library at this point. Based on the URL that is active, it loads the right component. A pattern we see frequently is to have the ComponentDidMount method call Ajax to load data and then dispatch an action to have the data stored in Redux’s store. Saving a value in Redux fires an event that the data in the store has changed which then notifies all the components that are listening to the store. The chain of reaction is fine, but I’d rather not have a component start the process of the data fetching. The first reason is that a component should be very dumb. The mounting of a component which only performs display and dispatches operations does not necessarily mean that we want to fetch the data. A change in the route, on the other hand, triggers the need for new data. Therefore, in this architecture, the loading of data is driven by a custom middleware that looks at the route change and executes the proper calls that will fill up the Reducer.
##Business Logic
Business logics are the core of your system, especially when it is more than just a CRUD application where we take data from the server and throw it on the screen. In this architecture, all domains have their custom middleware. A logic may request data from an API, manipulate it, ask for more data and when ready, store the data in Redux Reducer. The ideal position for business logic is in the middleware since they have not only had access to the actual store (getState) but also to the API call. It can be asynchronous with the help of Redux-Thunk and fit well in architecture with pre and post middleware that we will see soon.
Normalization and Store
Data comes in many formats, and sometimes some entities are part of many data branches. Normalizing the data means avoiding any duplication of data inside the store even if the data is used in many branches. Normalizing should always be done before sending the data to the Store. The reason for having a middleware to normalize the data and then send it to Reducers makes sense. Avoiding duplication is key to a stable system where the store is a source of truth.
Pre and Post Middleware
Every time an action is dispatched, the lifecycle flow of information goes from React component to middlewares to reducers to the store which then notifies the React component. The pre and post middleware are middlewares located before and after the domain middleware.
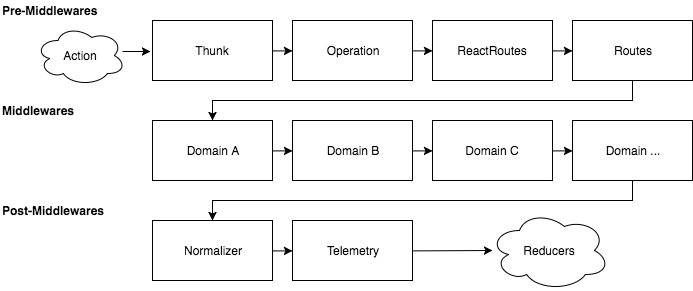
Pre-Middlewares in this architecture are middlewares for Thunk, operational, routing and authentication. Post-Middlewares are for normalization and telemetry. Let’s take a look at some of them to have a better idea. Post-Middleware prepares the data for business logic ones where the domain logic will be executed.
The Redux-Thunk library is the one that transforms actions to be asynchronous. This is quite useful as it enables us to dispatch multiple actions from a single middleware. For example, when you are loading data, you might dispatch an “is loading” action, when the data received is “data loaded” action and finally “save data in reducer” action.
The operational middleware is not required here, but I found it useful to associate a unique ID to a lifecycle flow. This data is used to tag logs into a specific lifecycle.
The routing middleware is divided into two middlewares, which are used to pass the routing information into the system. The first is the official one from React-Redux which handles the history/location data. The second one is more interesting since it’s the one in which we will manually analyze the route and figure out if we want to load data when a route has changed. This middleware can dispatch many actions. For instance, it can set the active entity by looking at the URL, dispatch a “loading” action for a particular set of data, and deconstruct the URL to know if a whole page is changing or if the URL is for a deep link which may require different actions to be dispatched. In the end, this middleware’s role is to handle the application logic regarding a route change.
The authentication middleware is the one that can look if the authentication token/cookie is still valid; if not, to request for a refreshed token before continuing the dispatch of action. I often queue every action until the authentication is validated. It can also be used as an authorization gateway if a particular credential fails to redirect. Being early in the pipeline, you can block it easily if needed.
Jumping to post-middleware, the most obvious one is the middleware that normalizes the data. This middleware listens to all activities that have a role in saving data to the reducer. It will normalize the data and send multiple dispatches to reducers. I recommend sending one dispatch per entity type since you can have a lot of reducers that are doing different manipulation per type. Since you should have one reducer per entity, it makes sense to have a more granular dispatching process. In the end, reducers will benefit by having a simpler immutability logic that is targeted to the reducer itself.
The last post-middleware can be a telemetry one where you may want to capture some actions for telemetry purposes. See this middleware as a logging middleware that avoids cluttering domain middleware.
Conclusion
This architecture is not fancy, making it shine by being easy to read and to change. If you have a new page to build, you only need to create your dummy React component, a middleware for the page if it’s not from an existing domain and adjust the normalization and reducer (if new entities are required).