
Adding an Embedded Vector Search in my Next JS SSG blog
Posted on: 2025-06-01
Context and Constraints
The last time I had a search on my blog was when it was hosted using WordPress. Using Next JS static site generation (SSG) for my blog and hosting it on GitHub Pages, I needed a way to implement search functionality without relying on a backend.
Summary of the Solution
I implemented a vector search using Python that generates a vector representation of my blog posts at build time. The build stores the vector data in a JSON file, which represents numbers for each post. The browser can then download the file and perform local searches. Using available libraries, the SSG does not perform the search; instead, it serves the vector file. A client-side React component takes the user input, converts it into a vector, and searches the local JSON file for similar posts. It is swift! The feature is available to try on this website (look for "search" in the header). It is so fast that it performs the top 10 on key presses. The drawback is that for approximately 800 blog posts, the vector file is about 2 megabytes to download (gzipped).
Generation of the Vector File
The generation of the vector file is less than 25 lines of Python code. The code leverages the Sentence Transformers library to convert the content of each blog post into a vector representation. The vectors are stored in a JSON file along with the metadata of each post (path, filename, and title). The metadata index is the same as the vector index, so the client can easily find the post corresponding to the vector search result. The metadata is used to display the search results in the React component.
Here is a snippet of the code that generates the vector file:
def generate_index():
model = SentenceTransformer(MODEL)
index = []
embeddings = []
counter = 0
for root, _, filenames in os.walk(BLOG_POSTS_DIR):
for filename in filenames:
if filename.endswith(".mdx"):
path = os.path.join(root, filename)
with open(path, 'r', encoding='utf-8') as file:
content = file.read()
embedding = model.encode(content, convert_to_tensor=True)
index.append({
"path":path,
"filename": filename,
"title": content.split('\n')[1].replace('title: ', '').replace("\"","").strip()
})
embeddings.append(embedding)
embedding_matrix = np.array([embedding.cpu().numpy() for embedding in embeddings])
# Output for the website
if not os.path.exists(OUTPUT_WEBSITE):
os.makedirs(OUTPUT_WEBSITE)
with open(OUTPUT_WEBSITE + '/index.json', 'w', encoding='utf-8') as f:
json.dump(index, f)
with open(OUTPUT_WEBSITE + '/embeddings.json', 'w') as f:
json.dump(embedding_matrix.tolist(), f)
The model is important as the client-side will need a client-side version of the same model.
Searching on the Client-Side
The search runs on the browser, but the blog is static. Thus, we need to split the TypeScript file into two parts: the client-side code that runs in the browser and the server-side code that runs at build time.
For the SSG, we instruct Next.js to Use the "next/dynamic" import, ensuring the component is only rendered on the client side.
import dynamic from "next/dynamic";
// Only rendered client-side - never during `next build`
const SearchClient = dynamic(async () => await import("./SearchClient"), {
ssr: false,
});
export default function Page(): React.ReactElement {
return <SearchClient />;
}
The SearchClient component is responsible for handling the user input, converting it into a vector, and searching the local JSON file for similar posts. It uses the same model as the one used to generate the vector file.
The core of the code is to use the @xenova/transformers library to load the model and perform the vector search.
useEffect(() => {
const loadAll = async (): Promise<void> => {
const [indexRes, embRes] = await Promise.all([
fetch("/output/index.json"),
fetch("/output/embeddings.json"),
]);
const indexData = await indexRes.json();
const embData = await embRes.json();
setIndex(indexData as Post[]);
setEmbeddings(embData as number[][]);
// eslint-disable-next-line @typescript-eslint/no-explicit-any
env.backends.onnx = "wasm" as any;
const extractor = await pipeline(
"feature-extraction", // https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.FeatureExtractionPipeline
"Xenova/all-MiniLM-L6-v2", // Must match the Python embedding model
);
setEmbedder(() => extractor); // Avoid rerender loop
setLoading(false);
};
void loadAll();
}, []);
Once the index and embeddings are loaded, the next function reads the user input, converts it into a vector, and searches the local JSON file for similar posts:
const handleSearch = useCallback(async (): Promise<void> => {
if (embedder === null || query === "") {
return;
}
// Create embeddings for the query
const output = await embedder(query, {
pooling: "mean",
normalize: true,
});
const queryVector = output.data as number[];
// Run the cosine similarity against all embeddings
const scoredResults = embeddings.map((vec, i) => ({
post: index[i],
score: cosineSimilarity(queryVector, vec),
}));
// Descending sort by score and take top 10
scoredResults.sort((a, b) => b.score - a.score);
setResults(scoredResults.slice(0, 10));
}, [embedder, embeddings, index, query]);
Challenges
I had several issues building the code using Next.js. The problem is a few dependencies that are not compatible with the browser. The solution was to use Webpack override for Next.js to exclude the problematic dependencies. The code below is added in the next.config.js file:
config.module.rules.unshift({
test: /\.node$/,
use: "null-loader",
});
if (!isServer) {
// Alias 'onnxruntime-node' to noop in client bundle
config.resolve.alias["onnxruntime-node"] = path.resolve(
"./noop-onnxruntime-node/index.js",
);
// Alias sharp to noop in client bundle
config.resolve.alias["sharp"] = path.resolve("./noop-sharp/index.js");
} else {
// Mark onnxruntime-node as external on server bundle
config.externals.push({
"onnxruntime-node": "commonjs onnxruntime-node",
});
}
The code resolves a few problematic dependencies using a loop fake implementation. The noop-onnxruntime-node and noop-sharp directories contain a single file that exports an empty object.
The null-loader is used to ignore the .node files that are not compatible with the browser.
export default {};
Automating with GitHub Actions
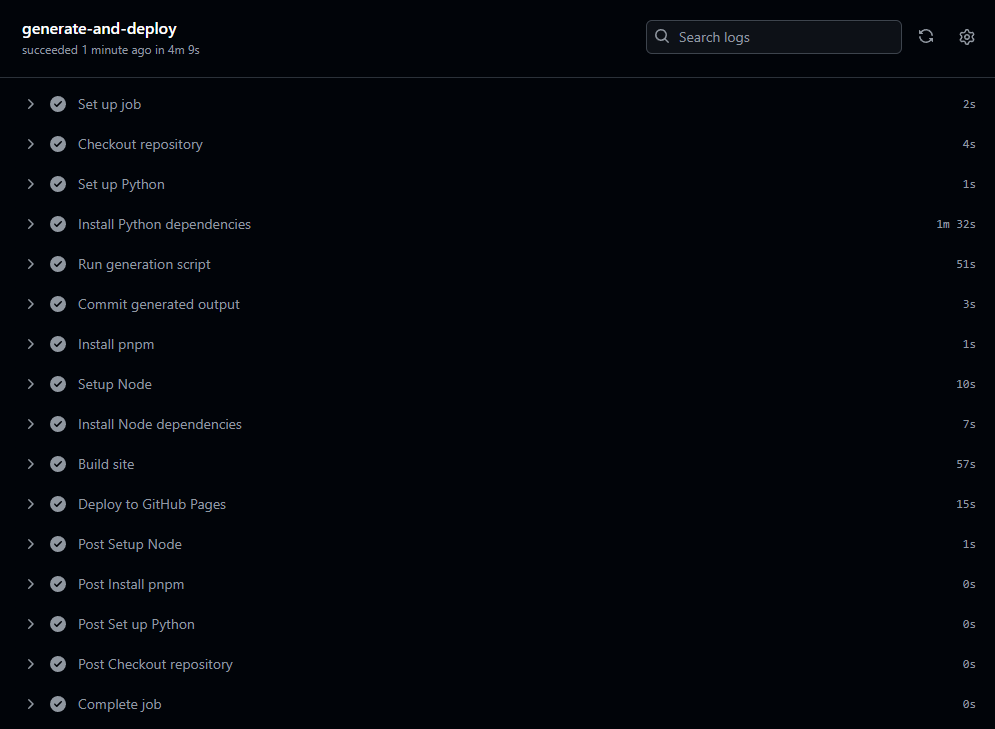
When I wrote this blog article, I had not modified the Github Action because I had an amazing 1 minute 40 seconds build time. I was foreseeing that the vector search would add a significant amount of time. Not because the execution is slow but because the Python code needs to run and the model needs to be downloaded. I was surprised that the build time was only 2 minutes 30 seconds. The Python code takes approximately 50 seconds to run, but it includes 90 seconds of download and installation time for the Python dependencies. I decided to keep the GitHub Action since it does everything in 4 minutes and 10 seconds, which is a reasonable time for a personal website.
Conclusion
While the search adds a few megs, it is limited to the user who clicks "search". From there, the browser caches the JSON files. Returning to the page is quick. The initial cost allows a fast search experience. Each key press generates a search that is under 20 ms.