
The CAP Theorem Explained
Posted on:
The CAP theorem consists of three characteristics that are pillars to distributed system. The premise of the CAP theorem is that you can only have two of the three characteristics enabled at the same time. But is that true?
First, let's define a distributed system. A distributed system is a solution, software or product that span on many servers. For example, you can have a web server that communicate to a database that reside on another server.
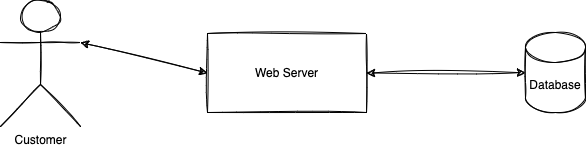
The example is simple and highlights a significant flaw: it is not supporting the P of the CAP theorem. The Partition Tolerance, the P, is often the less understood of the three. It is also the one that is defaulted as one of the two that must be present -- with reason. The information travels your system without P but never reaches the desired final state.
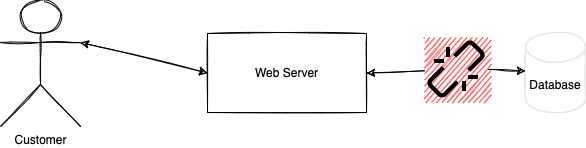
CAP Explained with a Web Server and a Database
Partition Tolerance
In the example of having a single web server that communicates with a single database server, we are paying the price of not being resilient. For instance, if one of the two servers turns off, the system cannot serve the user. To be partition tolerance, we need to have the system continue to operate if one of the servers is overwhelmed, having a software issue, or is entirely down. The partition means that a part of the system can break and the system as a whole continue to operate. The operation might not be ideal, might not offer the most updated values, and can be slower, but it is guaranteed to continue to tolerate some breakup in the flow of information.
In the web server and the database example, we could have a load balancer that redirects to many web servers that communicate to a database cluster. In that case, if a web server receives many requests, the load balancer can distribute the requests among the web servers. Similarly, the collection of databases allows different strategies like sharding or database replications that will enable one node to shut down without losing information.
If we flip the perspective in a non-partition tolerance system, if we want to have a system that performs the expected task, we would need to guarantee that the data that travel the system never fail. Because it is impossible to ensure, we must build a system with an architecture that assumes that exceptions will occur or a node will fail. Then, the system can react and adapt the request to complete the expected operations.
Availability
The availability characteristic of the CAP theorem stipulates that every request receives a response. The response might not be the latest version of the data, but you are receiving something. To be available means that a part of the system presents to deliver a response. In the example with the web server and the database, the data might be coming from a slave node that did not receive yet the latest update of the data from the master. Still, the web server responds with something. For the user, the service is available since the user inquires information and receive data. By being available, we ensure that the consumer receives something relevant but maybe not the latest version.
Consistency
Consistency is the freshness of the data that the user can expect from the system. In the availability characteristic, we defined that we might receive information that is not the latest version for the price of constantly receiving a response. The consistency is the characteristic determining how close to the newest version we want to serve the user. The higher the consistency, meaning the fresher the data is returned, the more the availability will decrease.
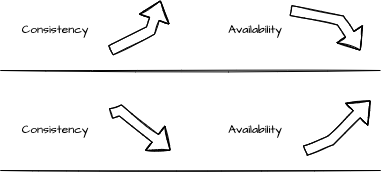
The consistency can be broken into three levels:
- Weak
- Eventual
- Strong
A weak consistency means that when a piece of data is changed, the consumer who requests the information may or not get the change. When adding a new bit of information, a user that inquires about it might receive nothing. Note that receiving nothing respect is available. The web server might check the database, reach a slave node, and read nothing. Then, it returns the user nothing. The request-response was available. The consistency is weak because we know that there is something to return.
In a weak consistency, the same user (or another user) can request the same information and receive a different result. For example, if two users request the same information but are reaching another database node during the travel of the request. A possible scenario is that one node has been updated with the latest version while the second one is yet to be updated. The result is that one user receives the newest data while the second one gets an older version.
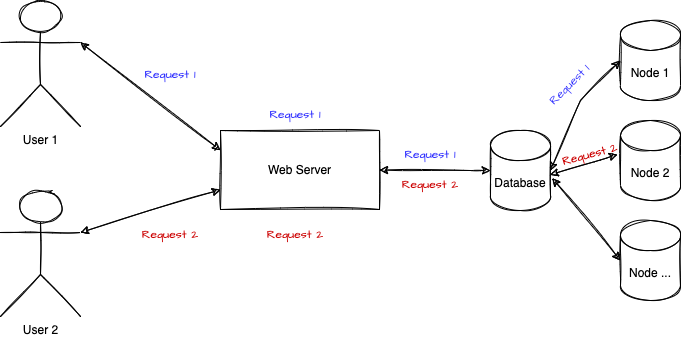
The eventual consistency is a step better where the timing between inconsistent and consistent is reduced. Typically, you can see inconsistency in the data for less than a second. It means that, for most scenarios, to be available and have a good user experience, we pay the small price not to be 100% consistent, but most of the time, the system appears to be consistent.
On the other end, a strong consistency prevails to always return the real and unique latest version of a piece of a data at the cost of the availability. Meaning, that a strong, consistent system prefers returning an exception to returning something not true. To be strongly consistent, overhead must be in place to ensure that every part of the system acknowledges receiving and persisting the data, a challenge in a distributed system. The more a system is spread with different nodes, servers, technologies, the harder it becomes to ensure that every piece of the puzzle is synchronized. The cost of consistency is high as it reduces performance across the whole architecture.
Hence, even banking systems are eventually consistent. It is why a user can make overdraft money and that there is a delay to receive funds, etc. However, instead of being strongly consistent, the system handles different features like overdraft fees and up-front mentions of 24h delays to receive funds.
Basic Example
Let's revisit the consistency, availability, and partition tolerance in a more illustrative to re-enforce our understanding. The example will grow in complexity at each step we work on improving a portion of the CAP. The simplicity of each step forgoes many details solely to emphasize how enhancing a piece of CAP impacts each other.
Step 1: Fragile CAP
Imagine starting a business where people send one worker an email to order flowers for someone and a specific date. At that point, the system is barely distributed: it is all local. From the previous example, there is the email server, and there is you who read the email and write down the order of what kind of flower and at which date to deliver and from who. You can store everything in a local spreadsheet.
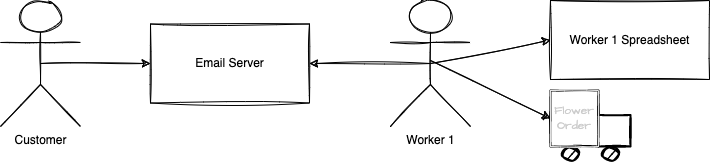
In the perspective of the CAP theorem, the consistency is strong. Strong because you are the only one reading the emails, the only one to insert, update or delete entries in the spreadsheet, and the only one to perform the task to order the flower for the person at the desired date.
The availability is not as impressive. First of all, the email system is not direct: it is passive. The worker has to get into the mailbox and check for new inquiries. Also, the worker has to be present at any time of the day. If someone asks for flowers at 6 pm on the same evening, the worker might miss the order if you were not online until the next day.
In terms of partition tolerance, if the spreadsheet gets corrupted, the email server is down, or the worker is taking the weekend off, the system cannot proceed with the information, although the steps to have a persisted track of what needs to be done.
Overall, the C is fine at the detriment of the A and P.
Step 2: Increasing Availability
To increase the availability, we improve with a second worker living overseas. It allows breaking the day into two shifts of 12h each. Hence, if someone puts an order by email at 6 pm, the other person will do if you cannot read the email.
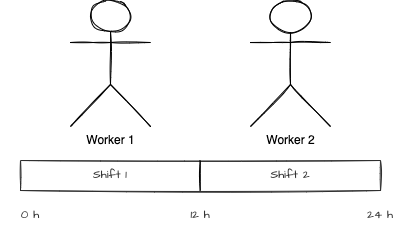
The A is up, but something is still not ideal. Each person is keeping a spreadsheet. If a customer writes an email at 6 pm and then writes one at 8 am to modify the order, the person reading the email might not have the initial order in the spreadsheet.
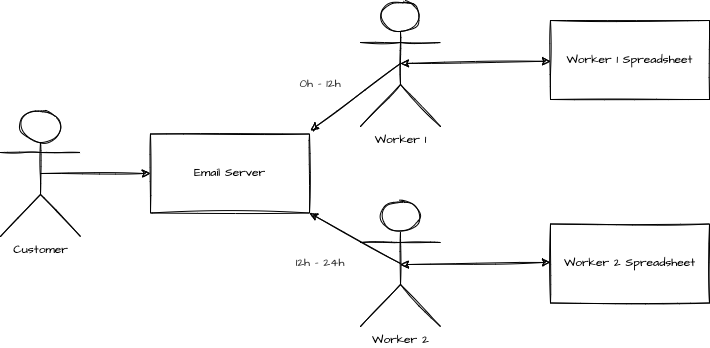
The increase of availability created a gap in the consistency where the information can be stored in two different places and never synchronized.
Step 3: Increase the Consistency
To solve the consistency issue, the person who read the email also writes another email to the other. Hence, if a modification or insertion is performed in one local spreadsheet, when the other person starts a shift, can read all the emails from the other person and update its spreadsheet.
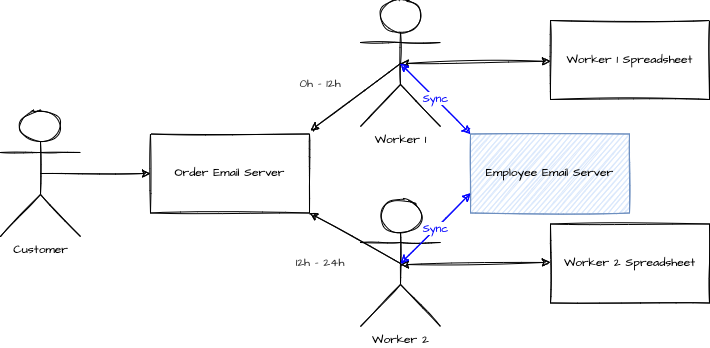
The data is duplicated. With some delay, it eventually becomes consistent at the beginning of each shift. The problem with the approach is that to mark the order as completed; it has to be more than only saved in the local spreadsheet. To have an order completed, it has to be persisted in the spreadsheet, and be sure that the email is sent to the other person. The additional step of confirming that the email is sent reduces the person's availability to read another email for a new order. It takes some time to write the email and ensure it is sent. Then, there is also the problem: we are only sure that it will eventually be consistent since we do not know when the other user will read and then write to its spreadsheet. If the other user that starts its shift in the morning does not check for the updates, the data is not consistent.
Step 4: Keeping Availability Hight and Consistency High
To ensure a high consistency, the workers communicate synchronously with each other before each beginning of a shift. The synchronization ensures an actual exchange of the order from the last active worker spreadsheet. There is an acknowledgement that they know they need and are synchronizing.
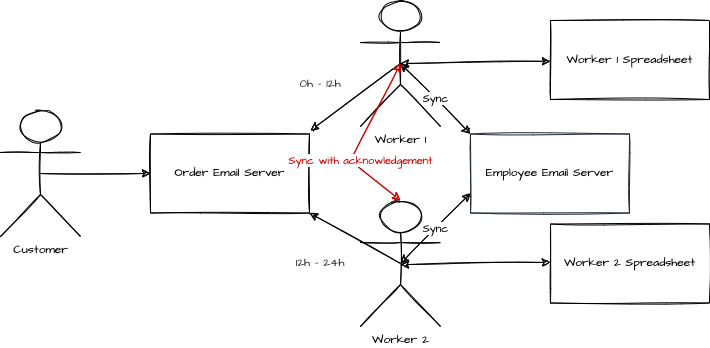
During that time, the availability might be reduced since the person on-duty to read customer emails is doing something else but overall still can fulfill the order with some delay; hence remains available. The consistency is substantial since the spreadsheet is up-to-date until the change of shift for the rest of the shift. However, a problem arises with the P. To be partition tolerant, the information must flow all the time. Currently, the system is partition tolerant because the information received from the email is transcribed into the spreadsheet. However, if the worker does not add the information in the local spreadsheet and order the flowers directly, the data is not written on the next synchronization. The flaw is a break of communication. Even more fatal, if one user is sick for its shift, the information is stuck in the mailbox. If the user writes for an update for the next person shift, that user will not see the initial request. The system is partially broken.
Step 5: Getting Partially Tolerant
To be partition tolerant, the mailbox system sends a copy to both workers all the time. When the worker is active on the shift, proceed with the information, it replies to the email saying that it has been updated in the spreadsheet.
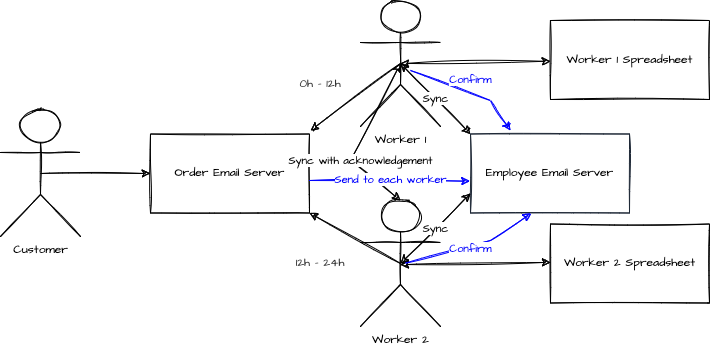
If the worker does not work on a shift, the next shift worker can backtrack which email in the mailbox has not been handled in the spreadsheet and update its local copy. The problem is the availability. During a whole shift, 12 hours, the orders were stall. Another that needed to be sent within a few hours would be a lost of business.
Step 6: Getting Modern
The system appears to be available but relies on the mail server, the ordering system changes to a website. The website increases availability because the user fills a form. Hence, the workers do not need to scan a free-form email. Also, using the website instead of email, the availability increase by avoiding issues with spam filters and other challenges of the SMTP protocol.
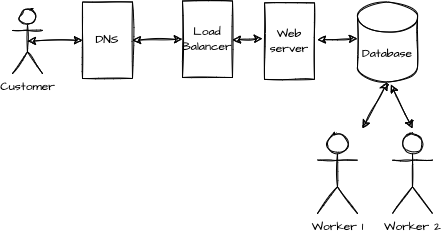
The web server saves the order into a database instead of a spreadsheet. It allows workers to extract the order and perform the actual shipping of the flowers. During the creation of the system, to ensure partition tolerance, many web servers were created in many geographical regions. Similarly, the database is replicated. The replication improves the partially tolerance characteristic.
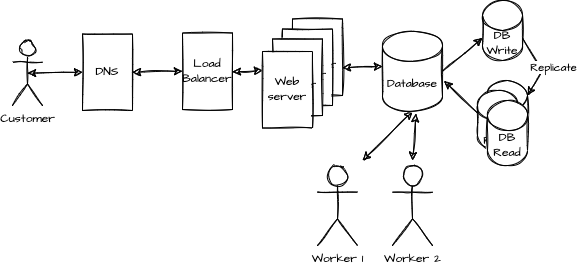
Although the system looks more robust in terms of partially tolerence, the consistency is eventual at best. The system is strongly available with a website that allows the user to fill an order and edit a previously created. But, the data might be returned from a database node that has not yet been updated, returning to the user information that is not up-to-date.
Step 7: Increase Consistency
In an attempt to improve the consistency, we trick the user into displaying a local copy of its browser storage, and hence the user sees the latest version until the back end (databases) are consistent. The solution is not flawless since users might use another device and see an inconsistency. But, the design is eventually consistent and covers most use cases transparently. A portion of the complexity is transferred in the frontend single page application (SPA), verifying if the order data is already locally available before fetching to the web server. The SPA logics knowns that for a determined period to bring from the local storage to display the information to the user. It gives time to the backend to be consistent. Once consistent, requests are generating consistent deterministic responses.
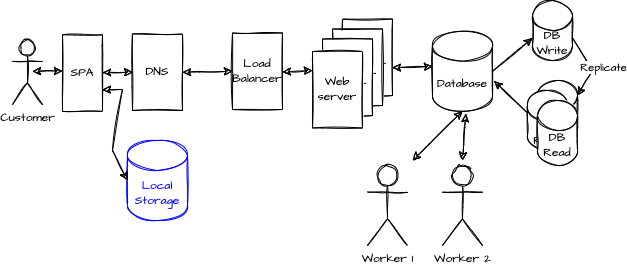
Another alternative could have been to ensure that the system read the information again from the write server until all the database read nodes had received the latest information. But, again, increasing the consistency involves more technical challenges and reduced availability as distributed locking mechanisms are involved.
Step 8: Increase the Availability
However, as the website becomes more popular, a need of backend cache is needed. A key-value solution is implemented, giving a fast access to the data. The cache is updated every time the data is persisted in the database. If an order is present in the cache, the cache returns the order instead of one of the database nodes.
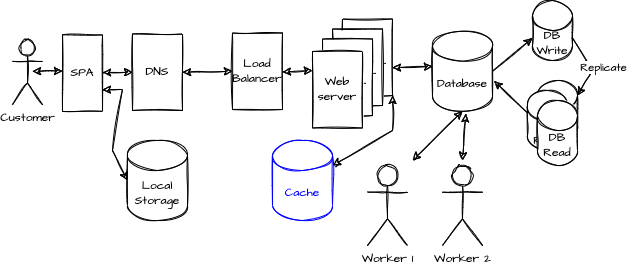
The availability is faster has the response for each request is quicker. However, synchronizing the cache and the database introduce some latency.
Future Steps
As you can see, any change in a distributed system changes the variables around the CAP theorem. The small situation described can worsen if we introduce order workflow. For example, if many workers are working on the same shift. They might read the same order to perform the actual flowers shipping. How can you ensure that two workers are not processing the flower orders? In that perspective, the consistency must be strong at the cost of availability. The system might lock the read of who can read the next order to proceed. Or, the system might have an algorithm to determine which worker can see which order to proceed. Or, the process might be that a worker needs to change the state of an order to "being processed" before working on an order, and if there is a conflict (more than one worker is starting to work on an order) to notify all the workers.
There are infinite scenarios and variables to change in a distributed system. In the end, it all depends on the business model. There are many options. For example, an architecture can have different areas of a system with different CAP characteristics.
Can we have the three?
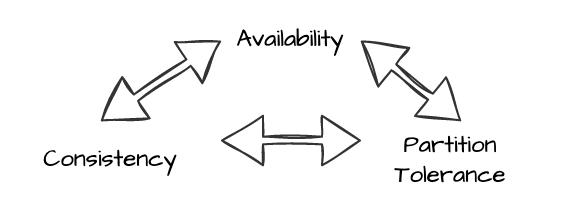
The CAP theorem appears to be simple on the surface. However, as we tweak a system to be stronger in one characteristic, we slowly feel that it weaken another portion of it. Then, going to another characteristic starts to degrade the two others. Hence, having a system that is perfectly CAP is unreachable. Nonetheless, it is possible to navigate a solution that appears for the end-user to be responsive and has limited drawbacks. Having a highly available system, with a strong consistency while having a partition tolerance enabled is utopic.
Conclusion
The CAP theorem is something that is a mix of simple concepts but also hard to grasp in practice. However, it remains a theorem that most distributed architecture sits on. Thus, it is vital to understand the limitation of an architecture, and the evolution of a system can sway the priority on different CAP characteristic as time progress.
The most important part is to remember:
- Availability → A request provide a response
- Consistency → Control the freshness of the data included in the response
- Partition Tolerance → How strongly a request will have its data navigate the whole system as intended