
YouTube Streaming Radio with More AI
Posted on: 2026-02-05
The Context
I recently built a web application that allows me to queue YouTube videos from my phone and stream only the audio back to me. I've been using it during my commute for over two weeks now.
I've since improved several parts of the system, such as having AI suggest other videos to queue based on the last few tracks I listened to. I also added the ability to generate a summary of all the audiobooks I listened to and create an audio summary that I can listen back to.
Streaming vs Downloading
One technical improvement I made was changing how audio is handled. Previously, I relied on FFmpeg to stream audio directly to the browser, which caused multiple issues. If the connection was unstable (for example, switching from Wi-Fi to 5G), playback would cut out even with a retry mechanism. The scrubber (the timeline showing playback progress) never displayed the full duration. Speed changes, such as 1.2×, also interfered with buffering and added significant complexity to the workaround.
Instead, I now download the full MP3 on the server and then download it completely to the mobile device. The file size averages 15–20 MB, and this approach fixes all of the above issues. When tracks are queued, I pre-download the MP3s so the wait time is no longer about downloading and converting the audio, but only about transferring it from my mini-PC (the server) to my phone.
I also keep a local copy of the MP3s for the last 15 tracks, which allows me to quickly go back to a previous audiobook if needed.
This change was a good learning experience. I am using Claude as part of an experiment with assisted LLM development, and it initially stored cached downloads in /tmp/, which does not persist files after a reboot. I had to change the storage location to something more permanent and manually remove older MP3s when needed.
Suggestions
Sometimes I'm on the run and don't have time to manually select a YouTube video to listen to. To address this, I added a button that sends a request to the server to fetch the last 10 audiobook summaries from Trilium (my note-taking app, where I store one note per audiobook summarized with AI).
Using those 10 summaries, I ask AI to generate a one-sentence theme. That theme is then used to search YouTube, producing a list of candidate videos. I filter out tracks I've already listened to and queue the rest. The entire process takes about one minute, which is perfect for tapping the button, getting in the car, and hitting play.
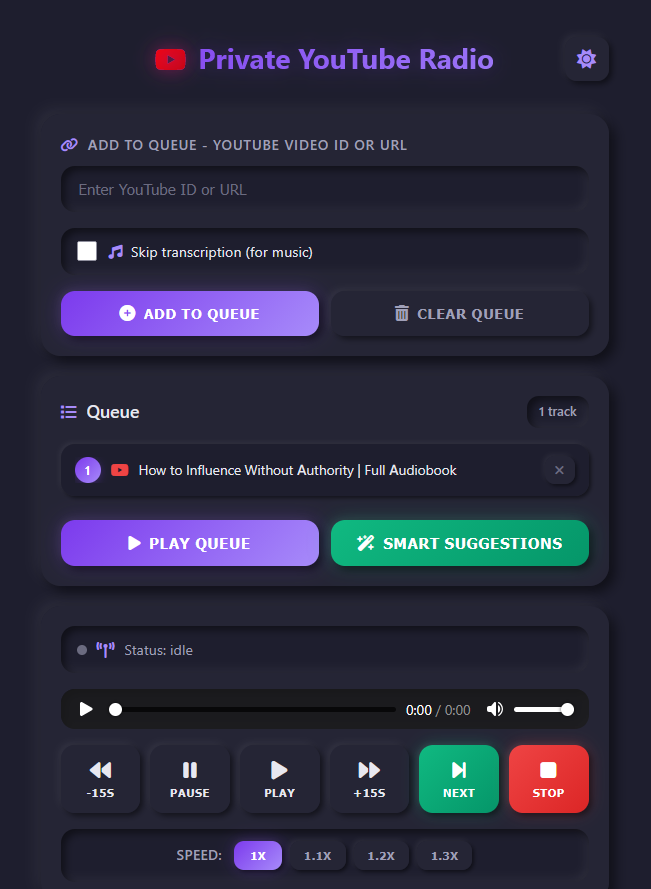
Summary of Summaries
Each audiobook has a corresponding note in my Trilium app. This works well, but because I use the application frequently, I end up with around 20 new notes per week. Even reviewing summaries starts to take time.
To solve this, I added a background job that runs at the end of the week. It summarizes the last seven days of summaries into a single new note. I then use the ElevenLabs API to generate an MP3 of that weekly summary and automatically queue it. An entire week of listening can be condensed into 6–8 minutes of audio.
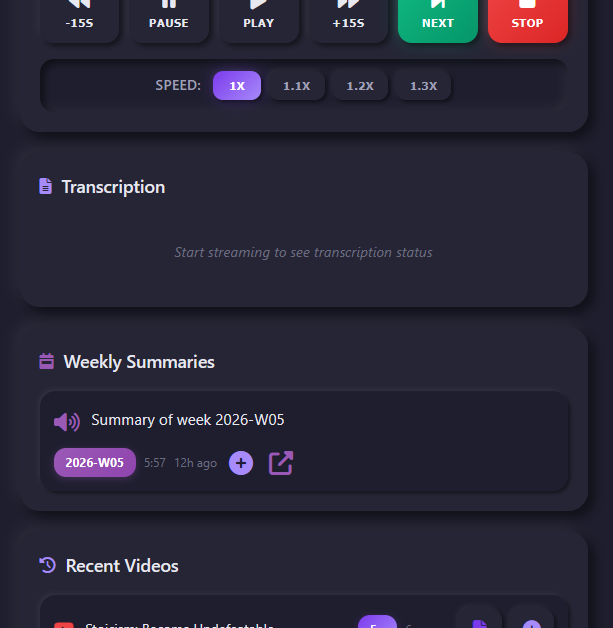
UI Improvements
I added several UI improvements, including both light and dark themes. The light theme is better when driving during the day.
I also adjusted playback speeds to 1.0×, 1.1×, 1.2×, and 1.3×. I previously experimented with higher speeds, but beyond 1.5× I found it difficult to drive, listen, and think clearly at the same time.
The weekly summary view includes a dedicated section where I can easily play the audio summary or read it directly from my phone.
Token Stats
I added token cost estimation to the system. Every request sent to the LLM records both input and output token counts. A dedicated page displays the cost per model. The system stores this data in a SQLite table, making it easy to query and analyze.
Code and Claude
This project is also an experiment with Claude Code. The results have been mixed. Claude's confidence is high, but it often produces duplicated code, non-working code (for example, calling Trilium APIs that do not exist), or solutions that are not optimal.
One recurring issue was that Claude repeatedly called AI for steps where results could have been cached in a workflow to avoid unnecessary costs. Claude is particularly challenging with the PRO tier. The advertised 5-hour window in PRO ($20/month) translates to roughly 45 minutes of active work. Because of this, I ended up doing more manual coding than expected.
To avoid burning through Claude's tokens, I frequently rely on Gemini, Google, or direct documentation instead. With unlimited tokens, I probably wouldn't.
I also noticed that while looping with Claude often fixes the code, it does not reliably update unit tests. In several cases, mocks that depended on function names were not updated, causing tests to fail. Additionally, when asked to change behavior, Claude often keeps the old function, marks it as deprecated, and has it call the new one instead of removing it. Without careful review, this can quickly lead to accumulating technical debt.
Finally, Claude does not always maintain a holistic view of the system it has built. Some features require natural adjustments when new ones are added, but Claude does not consistently make those connections, resulting in more required human intervention than expected.
That said, I can clearly see how Claude and other alternatives will become significantly more powerful in the future.
On that note, I am also running an LLM locally on my RTX 5080. The model is QWEN3.0-8B. It is very fast but only suitable for narrow, specific tasks. Claude, overall, is still about 50× better.