
A Single GraphQL's Schema for Internal and External Users
Posted on:
Imagine the scenario that you have a GraphQL schema that is consumed only by engineers of your organization. However, some engineers work on external facing applications while some other works on internal applications. The difference is subtle, but some information must remain confidential. While it might be more restrictive than most GraphQL that are fully public, there is the benefit that the schema is private and we can leverage that detail.
Internal vs External
In the scenario described, the GraphQL server is deployed into an Amazon VPC -- an Amazon Virtual Private Cloud. The environment is secured and the authorization is granted to only a limited to specific security groups.
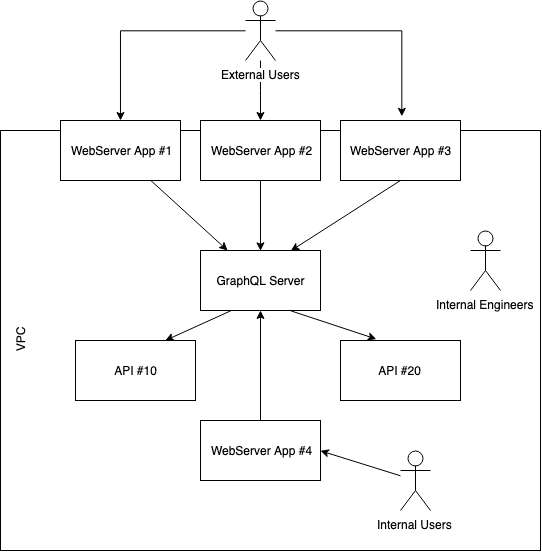
Internal vs External Environment
The challenge is not to limit the schema definition into an internal and external, but to have the external users not able to craft a request to access unexpected information. Because the GraphQL server is behind the VPC, it is not directly accessible by the user. The external application can communicate to the GraphQL server and every front-ends request to fetch data are proxied by the web server application. The proxy is important. It means that the browser of external users is not directly connected to the GraphQL server. Instead, the browser performs an AJAX call to the respective web server and this one, on the behalf of the user will conduct the GraphQL query. The proxy is conducted with the ProxyPass instruction of Apache.
Internal applications do not have many constraints but keeping the same pattern of proxying is a good habit. It simplifies CORS because the browser performs HTTP requests to the same server, and only underneath it communicate to other servers. It also simplifies the security by having a central point of communication (the web server) to communicate with backend secured services.
GraphQL Single Schema
An obvious solution is to have two schemas: one internal and one external. The solution is the only choice if you need to expose the GraphQL schema externally without exposing the definition of internal fields and entities. However, because I had the constraint of not exposing GraphQL outside, I could simplify the maintainability by having a single schema. The problem with many schemas is that it does not scale very well. First, when adding a field that is good externally, you need to add it twice. Then, when it is time to modify or remove, you need to keep in synchronization the different schemas. Any little boilerplate cause the engineering experience to be a burden but also is prone to errors.
In an ideal world, a single schema exists and we flag the field or entity to be only available internally. That world can exist with the power of GraphQL directive.
The GraphQL Directive Idea
GraphQL allows enhancing the graph's schema with annotation. Let's start with the end result which should talk more than any explanation.
type MyTypeA {
fieldA: EntityTypeA
fieldB: EntityTypeA @internalData
}
The idea is to add "@internalData" to every field that must be only visible to internal usage. The annotation marks field but also can mark a whole type.
type MyTypeA @internalData {
fieldA: EntityTypeA
fieldB: EntityTypeA
}
The idea is to have a single schema that had an indication that the field is added into a request will have some consequence. Because it is a single graph, the field appears in the interactive Graphql Playground and is a valid field to request; even externally. However, when invoked, GraphQL at runtime will be able to read the directive and perform a logic. In our case, the logic will be to verify the source of the request and figure out if the request is internal or not. In the case of an internal request, the data will be part of the response. If the source is external, an exception will occur and the field will be undefined.
How to build a GraphQL Directive?
The directive is two parts: one is in the GraphQL language (design time) and one is the logic to perform at runtime.
In any .graphql file, you need to specify the directive to let know GraphQL about its existence. I created a file with the name of the directive and added this single line. The directive indicates that it can be applied to a type (OBJECT) or to a field (FIELD_DEFINITION). The directive could also have arguments. For example, we could have a more advanced need to specify which role can access which field.
directive @internalData on OBJECT | FIELD_DEFINITION
The second part if to handle the directive. When merging all the resolvers and type definitions you can also specify the collection of directives. What you need to pass is a key-value pair with the directive name and the class of the directive (not the object). It means that you do not instantiate (new) the class, but only give a reference to the class.
const schemas = makeExecutableSchema({
typeDefs: allSchemas,
resolvers: allResolvers,
schemaDirectives: {
internalData: InternalDataDirective,
}
});
The class must inherit SchemaDirectiveVisitor. Then, because we have specified that it can be applied to a field and a type, we need to override two functions: visitFieldDefinition and visitObject.
export class InternalDataDirective extends SchemaDirectiveVisitor {
private static readonly INTERNAL_APP = ["app1", "app2", "app3"];
public visitObject(object: GraphQLObjectType): GraphQLObjectType | void | null {
this.ensureFieldsWrapped(object);
}
public visitFieldDefinition(
field: GraphQLField<any, any>,
details: {
objectType: GraphQLObjectType | GraphQLInterfaceType;
}
): GraphQLField<any, any> | void | null {
this.checkField(field);
}
private ensureFieldsWrapped(objectType: GraphQLObjectType | GraphQLInterfaceType) {
if ((objectType as any).__scopeWrapped) {
return;
} else {
(objectType as any).__scopeWrapped = true;
}
const fields = objectType.getFields();
Object.keys(fields).forEach(fieldName => {
const field = fields[fieldName];
this.checkField(field);
});
}
private checkField(field: GraphQLField<any, any>): void {
const { resolve = defaultFieldResolver } = field;
field.description = `🔐 Internal Field. Only available for: ${InternalDataDirective.INTERNAL_APP.join(", ")}.`;
field.resolve = async function(
source: any,
args: any,
context: GraphQLCustomResolversContext,
graphQLResolveInfo: GraphQLResolveInfo
) {
if (
context.req.appOrigin === undefined ||
!InternalDataDirective.INTERNAL_APP.includes(context.req.appOrigin)
) {
throw new Error(
`The field [${field.name}] has an internal scope and does not allow access for the application [${
context.req.appOrigin
}]`
);
}
const result = await resolve.apply(this, [source, args, context, graphQLResolveInfo]);
return result;
};
}
}
The directive converges the two entry points (field and object) into a single function. The two functions are called once when the class is instantiated by the GraphQL code at the startup of the server. It means that you cannot have custom logic in the visit functions. The dynamic aspect appends because we wrap the resolve of the field. It means that the actual resolution is executed but the code specified in "checkField" is also performed at runtime. In the code excerpt, we see that it checks for a list of accepted internal applications. If the field has the directive, it goes into the directive's resolver and checks if the origin if from the list of accepted internal application. If not, it throws an error.
A little detail, it is possible to inject a description from the directive that is set on the initialization of this one. In my case, I specify that the field is private and mention which application can access it. If a software engineer needs an application to be on the list, it requires a code change. This is not something that happens often and because a code change is required it involves a pull request where many people will have a look.
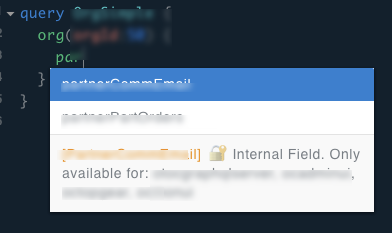
Example of how it looks from the GraphQL Interactive Playground. The engineer who build the query knows that it is an internal field as well as under which application the response will return a value
Conclusion
The more I work with different organizations, code bases, and technologies, the more I lean toward simplicity. There is so many changes, so many ways to get very deep into subjects and so little time. Getting into complex solution often cause the maintainability a nightmare or make some people very dependent. The solution of a directive in GraphQL took less than 150 lines of code and can scale toward the entire graph of objects without having a dependency on a system to manage many schemas. The security of the information is preserved, the engineers that consume the graph are aware when building the query (description) and while executing the query (error), and the engineers building the graph can add the tag to the fields or types which take a few seconds without having to worry about the detail of the implementation.
My Other GraphQL Blog Posts
- Getting Started with GraphQL for Netflix Open Connect
- Install Apollo Server to host a GraphQL service
- Apollo Server and Secured Playground
- GraphQL Context
- GraphQL Query with Argument
- Apollo GraphQL Resolvers and Data Source separation
- How to setup a TypeScript, NodeJS, Express Apollo Server to easy debugging with VsCode
- GraphQL Resolvers with Apollo
- Configuring Apollo Playground and API on two different URL
- How to automatically generate TypeScript for consumers of your GraphQL
- GraphQL and HTTP Telemetry
- GraphQL and TypeScript/React