
GraphQL Resolvers with Apollo
Posted on: 2019-02-26
In this article, we will discuss about two topics that concern resolvers and performance. So far, and by default, everytime a resolver is invoked, this one execute its actions which is mostly be to fetch the data. The problem is that in a graph there is potentially redundant information that will be fetched several time causing performance issue.
For example, a query on an object that is cyclic with cyclic information will cause duplication of call. Imagine querying for obj1->obj2->obj1->obj2.
The problem becomes gargantuan with an array of object. Imagine that you have a single query for each type that is in a big array, you would perform many hundred or thousand of requests while in practice you probably would have use a special endpoint that return a batch of all the information.
The good news is that GraphQL has the concept of resolving at many levels. It is possible to resolve at the root level, which mean directly at the query level. But, alos at any edge which is great for an edge into an array of object or a heavy object that require special need. How, it is possible to resolve at the field level which can also be interesting in the case of a particular field that needs to be tackled differently of its general type.
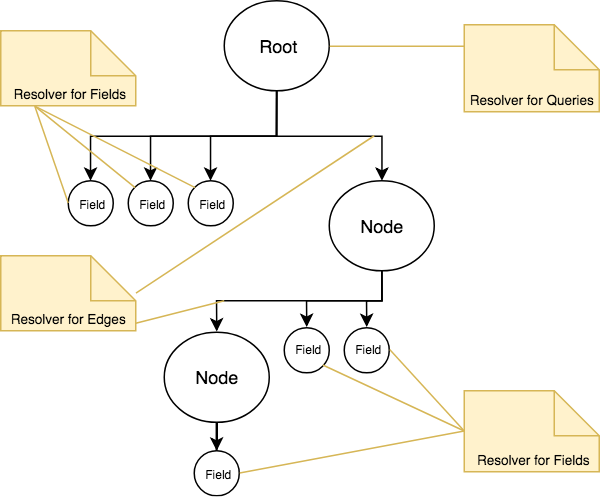
Three different resolvers: Query, Edges and Fields
The two concepts we will investigate is "look-ahead" and "batching". The look ahead is the idea of looking in the query schema and performing chirurgical analysis of what is requested. Batching is the of collecting all the desired data to fetch and fetch it once we are done traversing the tree. It means that if in the graph we have several times the same entity to query that we will only do it once -- at the end. From these two summaries, it is clear that one is to optimize the query in term of figuring out which would be the best while the second is to avoid redundant calls. The former can help for avoiding calling several endpoints by redirecting the logic into a single endpoint while the latter removes querying the same element.
Look-ahead
A parent children is the common scenario. Imagine a parent who has many children. GraphQL by default will call the resolver for the parent and then will call a single resolver by children. If you have the resolver of the parent fetching the parent data (1 HTTP request) and then one fetch at each child (1 HTTP request multiplied by the number of children) it can become not performant. Even if the GraphQL is connected directly to a database, it would not be performant on a big list of children. The database scenario is often easier to visualize. Instead of making several SELECT statement with a WHERE clause that specify a single child ID, we would do a SELECT statement with a IN clause that specify the array of IDs. That way, it would return a single query response with many rows. In REST, if you have an endpoint that allows the parent to expand the children, you can use that endpoint instead of the one that only return the immediate parent attribute.
In GraphQL, you can peek at what is being queried. The look-ahead notion is the exploration of what the user specified in the query. The information is available in the fourth parameter of the query. The parameter's type is "GraphQLResolveInfo". You can use a NPM package named "graphQLFields" that will give you an easy way to access the information.
const fields = graphQLFields(graphQLResolveInfo);
Once you have extracted all the fields, you can check if the children node is being requested. If not, you can fetch the parent information without the additional payload (SELECT directly the ID without further data from children).
if (fields.sites !== undefined){
// Perform a more exhaustive query that will save us many small request
}
There is still one issue with the look-ahead: the children resolver is still called and will still perform the request. How can we notify the children that we already have everything we need in a clean way? This is where batching come in.
Batching
Batching is doing two things: cache and batch many ids. The whole idea is that instead of calling directly your SQL or REST endpoints, you call the DataLoader. It is a layer of abstraction that will check if we already have a promise for the key requested. If so, it returns the existing promise. The promise can be already resolved which would be very fast. The DataLoader library is a NPM package that has its own TypeScript definition file which is convenient if you are writing your code in TypeScript.
Naturally, the DataLoader is taking an array of the key. Even if you want to request for a single element, the DataLoader will presume that you query for a collection. I will not go in this article about pattern that you can use other than mentioning that you could look at the number of ids passed in the DataLoader and take a smart decision about how to fetch the data. Worth mentioning, the load function of the DataLoader that is needed to get the information from the cache or the code inside the data loader (to fetch) can be invoked multiple times. The DataLoader will coalesce all singular loads which occur within a single tick and then call your batch loading function.
An effective way to work with DataLoader is to have a single DataLoader by way to query the information. For example, if you query a "parent" entity by id, you would have a DataLoader for "parent" by "id". You will have one for "parent" by "name" and one for "child" by "id", etc. The separation might sound redundant but a single GraphQL query does not ask for many entities in a different way, hence does not duplicate much.
A good way to keep everything tidy up is to define a class into which we can inject the current user's request. It gives all the security information like any authentication bearer token that the fetching code might need. The class trickle down the context information (user's HTTP request) by having the request passed in its constructor parameter down to the service that will fetch the data. In the following code, you can see the pattern.
export class DataLoaders {
private dataSources: GraphQLCustomDataSources;
public getParentByParentId: DataLoader<number, Parent>;
public getChildByChildId: DataLoader<number, Child>;
public getChildrenByParentId: DataLoader<number, Child[]>;
public constructor(requestTyped: IUserRequest) {
this.dataSources = {
sourceApi1: new Api1HttpService(requestTyped),
sourceApi2: new Api2HttpService(requestTyped)
};
this.getParentByParentId = new DataLoader<number, Cache[]>(parentIds => {
const proms: Promise<Parent[]>[] = [];
for (let i = 0; i < parentIds.length; i++) {
proms.push(this.dataSource.sourceApi1.getParent(parentIds[i]));
}
return Promise.all(proms);
});
// And so on for each DataLoader...
}
}
The code above is a short version of what it can be with two entities: Parent and Child. In reality, you would have way more DataLoader and might want to breakdown each detail into a separated file and use the DataLoaders class as a facade to all the logic. The goal here is to have a single point of initialization to get the HTTP request passed down to the implementation of the data source.
Still, there is an issue. We are caching the DataLoader of the Parent entity, not the Child entity. It means that when the GraphQL traverse and invokes the children resolver, that this one will call the DataLoader that request the child information by child id, not by parent ID. There are many patterns. You could invoke the parent DataLoader and check if the data is already present. You can also have the parent DataLoader primes the child DataLoader. Priming the data means to set in another cache the data. The following code can be added to the DataLoader previously built. Now, the GraphQL invokes the DataLoader of the parent, get the data and populate the parent's cache. Because it has the information about the children, it loops the collection and primes the child's DataLoader as well. The traversal continues and the child's resolver calls the child's DataLoader that has a promise resolved with the child data.
children.forEach(c => {
this.getChildByChildId.prime(c.id, c);
});
From there, you instantiate the class once in the Apollo's server configuration. The instantiation will occur at every request, hence no data is mixed between users.
async function apolloServerConfig() {
const serverConfig: ApolloServerConfig = {
schema: schemas,
context: (context: GraphQLCustomResolversContext) => {
const newContext: GraphQLCustomContext = {
loaders: new DataLoaders(requestTyped)
};
return newContext;
},
// ...
}
}
Summary
The DataLoader library is useful to cache data during a single request when GraphQL is traversing the tree. A parent node can look-ahead and load in batch information reducing the number of future requests. The DataLoader library cache the result for each DataLoader. In the code presented, the DataLoader was filling up the parent loader which might not be useful in the situation but by priming the child's DataLoader jettisoned all costly subsequent in the child's resolver.
Related GraphQL Articles
- Getting Started with GraphQL for Netflix Open Connect
- Install Apollo Server to host a GraphQL service
- Apollo Server and Secured Playground
- GraphQL Context
- GraphQL Query with Argument
- Apollo GraphQL Resolvers and Data Source separation
- How to setup a TypeScript, NodeJS, Express Apollo Server to easy debugging with VsCode
- GraphQL Resolvers with Apollo
- Configuring Apollo Playground and API on two different URL
- How to automatically generate TypeScript for consumers of your GraphQL
- GraphQL and HTTP Telemetry
- GraphQL and TypeScript/React