
GraphQL Extension to Collect HTTP and Resolvers Telemetry
Posted on: 2019-04-09
The more my graph was increasing, the more resolvers I built. The more resolvers I had, the more data loaders I created, the more HTTP endpoints I had to call and so on. The complexity of the code was rising as well as the possibility to have a catastrophic amount of HTTP requests to be performed by GraphQL. The amount of log by using the console was not only polluting the source code by having a line in each resolver and HTTP method but also couldn't make it easy to collect the data for future analysis or to emergency cancellation of a GraphQL query if the amount of HTTP rise beyond a reasonable threshold.
The idea I had was to see if there is a way to hook into GraphQL to collect the data at a higher level instead of being at each function. I am using the Apollo library and the answer is yes! There is an experimental feature named "extension". The documentation is dry and does not explain much but with some breakpoint and Visual Studio Code, I was able to build a simple extension in a few hours. Here is the result.
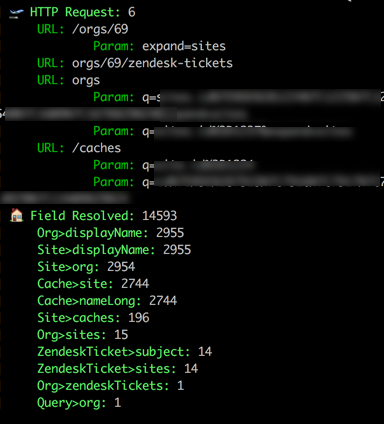
A GraphQL Request with its HTTP requests
The first requirement is to create the extension. It must inherit the GraphQLExtension class which is generic. The generic type needs to be your context type. Having access to the context is primordiale because it gives access to your user information. I assume that once authenticated the user is set in the context. Also, it gives you the possibility to inject statistic into the context throughout the exploration of the graph. In my case, I am using the context to collect information at my data service layer where all the HTTP requests are performed.
export class DevConsole<TContext extends ApolloConfigurationContext>
implements GraphQLExtension<TContext> {}
There is two importants function that you can override. The first one is requestDidStart which is invoked when a GraphQL request is made. It means that when a context is created and it that case a "request" is the GraphQL request and not all HTTP request performed by GraphQL during that GraphQL's request. The function return a function. The return function is invoked when the request is completed. It is the place to output into the console all your statistic or to send the information to your telemetry system.
public requestDidStart(o: {
request: Pick<Request, "url" | "method" | "headers">;
queryString?: string;
parsedQuery?: DocumentNode;
operationName?: string;
variables?: { [key: string]: any };
persistedQueryHit?: boolean;
persistedQueryRegister?: boolean;
context: TContext;
requestContext: GraphQLRequestContext<TContext>;
}) {
console.log("New GraphQL requested started");
return () => {
const yourContextData = o.context
console.log("Your data can be sent here");
};
}
The second function is named "willResolveField" and is executed at every node of your graph. You can know the parent field and your field.
willResolveField(source: any, args: { [argName: string]: any }, context: TContext, info: GraphQLResolveInfo) {
// Info has the field name and parentType.name
return (error: Error | null, result: any) => {
// ...
};
}
The next step is to plug the extension into Apollo GraphQL. The property "extensions" of ApolloServerConfig takes an array of extension.
const serverConfig: ApolloServerConfig = {
// ...,
extensions: [() => new DevConsole()],
};
I am using the RESTDataSource of Apollo as well to perform all HTTP request. The abstract class has the GraphQL's context. If you override the function willSendRequest, you can then have a global hook into all HTTP request. In that function, I am populating a property of my context that I named "stats" where I am storing each URL and parameters.
public willSendRequest(request: RequestOptions) {
const stats = this.context.stats;
// push data in the stats object
}
The documentation could be better in term of defining all the possibility. Nevertheless, with some breakpoints and a little bit of time I was quite satisfied to see what can be done. You can do much more than what proposed, for instance, you can calculate the payload size and get more insight into what is not efficient. For example, I realized in the process of creating another exception that was throwing an exception when a maximum threshold of HTTP request was reached was still letting GraphQL continue its traversal causing the exception to occurs on every future node. The solution was to clean up the response of redundant error using the overload function willSendResponse.
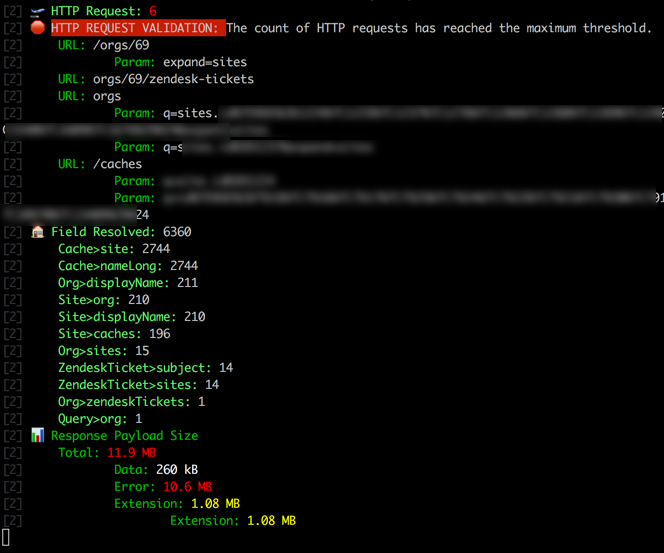
Bonus: Getting the size of the payload
There is a lot of possibility to get a clear view of what is happening behind the scene for maintainers and developers of the GraphQL service. The detail does not matter directly for the consumer who care about getting the data fast and accurately in the format requested and not about the complexity. However, the complexity if not well exposed to the team who own the service can be costly in term of resources. It is very easy to fall into the trap of assuming that everything goes as expected in a world where every GraphQL request is unique and can surface a scenario not well covered.
Previous GraphQL Posts
- Getting Started with GraphQL for Netflix Open Connect
- Install Apollo Server to host a GraphQL service
- Apollo Server and Secured Playground
- GraphQL Context
- GraphQL Query with Argument
- Apollo GraphQL Resolvers and Data Source separation
- How to setup a TypeScript, NodeJS, Express Apollo Server to easy debugging with VsCode
- GraphQL Resolvers with Apollo
- Configuring Apollo Playground and API on two different URL
- How to automatically generate TypeScript for consumers of your GraphQL
- GraphQL and HTTP Telemetry
- GraphQL and TypeScript/React