
Post-Mortem of my Asp.Net MVC Project, SQL Server, Redis and managed with VSTS
Posted on:
During winter 2014, I decided to re-write my old 2004 PHP stock simulator. My initial plan about what needed to be done changed just a few, since the beginning even if I joined Microsoft few months after. Most of the work planned got executed. With the move and the arrival of my first daughter, I had less time, so in the meantime, I merged all my posts about the first few months into this one. Having to maintain this blog and a dedicated online journal of my progress was too much. I am now in the final stretch and I can look back to tell what went good, what was wrong. This article will be what lessons I have learned during this adventure of 35 months.
Quick Recapitulation
The project started has a simple stock simulator built between 2004 and 2006, but mostly during the winter 2004. The legacy system was built in PHP (3 than 4 than 5), MySql and MemCached hosted in a Linux VPN. Some JavaScript was used with CSS. I remember that JQuery wasn't there and the web 2.0 was still very new. I had to do my own Ajax call using primitive JavaScript and ActiveX for Internet Explorer.
I do not have the real amount of time spent coding because development of features continued until 2010. Roughly, I would say that the core took about 100 hours, added by few big features around the next years. So about 5 x 60 hours and one big refactor of 100 hours, so overall around 500 hours.
Moving back to 2014, I had more experiences, access to better technologies and I achieved 75% of features in about 2000 hours. I will not paint a picture prettier than it is because the goal is to figure out reasons why this project took 4 times the original time. During the reading of this text, you have to keep in mind that while this system is new, the old one was still running with active, real, users. I wish I could have release a version before July 2016 (sprint 30) but the lack of features couldn't be justifiable to have a quick first release and iterate on it. I first thought to release the month before the delivery of my first baby (June 2015 / Sprint 17) but the amount of performance improvement, bugs and administrative features would have been missing, making the next month harder to develop and probably reduce the throughput of work.
Schedule
Everything was planned in sprints with VSTS. If you go see a my post, you will see screenshots who look already dated because Visual Studio Team Services has changed a lot since the inception of the project. Since I was the only developer, I decided to have 1 sprint per month which allowed me to have a fix set of features delivered every months. Most of the month was planned to have 2 hours per day, so a sprint was 60 hours. On the 35 months, about 6 months had less time being half capacity. These months were the few months before my move from Montreal (Canada) to Redmond (USA) for Microsoft. I also had 2 months slower when I my first daughter arrived. So overall, 29 sprints of 35 sprints went has planned. I knew I could do it since it's one of my force to be consistent.
However, I was spending more than 2 hours per day. To be honest, I planned to finish everything within 1 year. My baseline was the time it took me to do it initially. I was planning to do more unit tests, more quality, more design but since I already knew all gotchas and how the logic needed to be that the 1 year plan was reasonable. After all, 12 months meant 12 months multiply by 60 hours that equals 700 hours which give me a nice 15% more of the initial design with 25% features. Each sprint was frozen in term of what to do, so I couldn't add more features during that month or change my mind. On the other hand, I allowed myself to reshuffle the priority. For example, I pushed back performance tasks and the landing page quite a few times.
Reasons of slipping the schedule
How come it tooks me more than 4 times the original time is hard to say. Even if I have all my tasks and bugs documented in VSTS, I do not have the actual time spent on these work item. During the development, I noticed that I was getting late, thus started to interrogate myself about the reason. Few things that was slowed me down around the the 12th months.
First, I was working on that project while watching TV. I wasn't isolated, my wife was always with me in the room and we were talking and doing other little chore that I was in reality spending a minimum of 2 hours -- mostly 2h30min but in reality was worth 1h30ish. That said, after a full day of work, I think it's reasonable not to be at 100% on a side project for that many months. I also had a period of time, almost 8-12 months where I fell into several Entity Framework issues which was slowing me down. I fought all those issues and never gave up. In retrospective, I should have drop Entity Framework and that why I have now an hybrid model with Dapper now. My justification of keeping fighting it was that my goal was to improve my Entity Framework skills -- and I did. In many different job I had before this project and after, I was often the one to fix Entity Framework mysterious behavior.
Second, an other reason of some slowness was the initial design with several projects which caused the build time to take more than 2 minutes. This might not seem a problem and often not a full build was required so not really a 2min45sec, but still always around 1 min. Building 15 times per night cause a lost of around 5 hours per months. And in fact, when waiting, I was going on Twitter, Hackernews, Facebook thus taking more than just the minute. So the 5 hours per months ended up by probably be around 7-8 hours per months on a time frame of 60 hours it is a lot. I ended up with a new laptop with SSD and more ram + change in the architecture (see later in that post) which helped me to reduce the waste by more than half.
Third, having integration tests (test with the database) was hard to build in some situations, which I'll explain later. Each integration test was taking about 20 minutes to write, debug and test.
Forth and finally, quality has a cost. To be honest with myself, the PHP project had about 50 unit tests. The new one has 1800. The PHP's project had deep bugs that was there for more than 2 years; the new one is still very new but major bugs aren't still visible. Something also changed which is the rate of update in technology. Between the first month of this project and the current, I updated several third-services API, libraries version and this required some changes. I am proud that I kept the original plan with Asp.Net MVC, front-end generated by the server and aiming for Azure instead of falling in the trap of switching technologies during the development.
What have I learned about schedule?
Using VSTS helped me to stay focus or at least prioritize my work. I have over 1500 work items at this day. I was using a sprint approach using the Backlog and Board. I was planning about 6 months a head, with 2 months really more seriously. Always the current month frozen to be sure not to over-add. The rare time I finished the sprint earlier, I added more unit tests. I was adjusting work items (user stories and bugs) for future sprints time to time. At the end, I was able to do every user stories expect those concerning option trading and team trading which the legacy system supported that I decided to drop because of their popularity and the time required. My evaluation of the time for each work items was often underestimated by few hours. I always tried to split my work items in task of 1 to 3 hours which was okay until hitting major issue. Also, tests was longer than expected -- all the time. But, sometime, it was the other way around and I overestimated. At the end, I was more underestimated than overestimated.
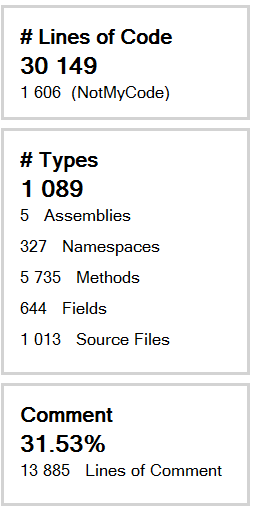
My conclusion on the schedule is that a single person project can have his toll when you hit a problem and can change drastically a schedule. A project that is planned to be on year can rapidly have months added up. While the primary goal was to learn and keep my knowledge up, I would say that a smaller project is better. That said, I still believe that a project most be significant to understand the impact on the maintainability. This one has 30 100 lines of code + 13 900 lines of comment, so more than 44k lines.
Finally, I would say that motivation is a factor too. I am very motivated and I enjoy the code produced which even after a hard day at work was making me feel good. Owning everything may have the bad side of being stuck for days which unrail a feature from 10 hours to 40 hours, but also have the benefit of having a code base that look like you want.
Architecture
The architecture was right from the start. I didn't do any major changes and the reason is that I knew how to do it. I not only maintained a lot of different projects, but also created a lot of them done in the past. PHP, Asp.Net webform, classic ASP, or Asp.Net MVC, at the end, a good architecture fits any languages.
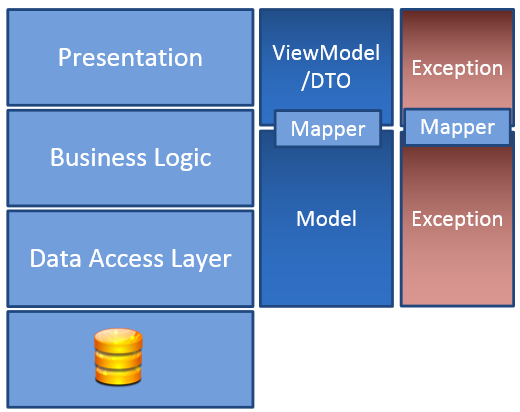
The unit of work wasn't that good. It's a recommended pattern by Julie Lerman in her Pluralsight training. The idea is very good, but Entity Framework Context is a mess and having the unit of work lives between logic was causing all sort of problem. While this pattern is a charm to work for testing, it's a maintainability nightmare. Adding logic between a simple load of data and a save could result of having Entity Framework Context being out of synchronization. I won't go more in detail in this post but you can find some details in this past post about why I wouldn't use Entity Framework.
Having the configuration at the same level of the repository is great, it means that this one can come from web.config, database, cache, etc without being important for any service layer (where the logic belong). Concerning cross-layer logic, it was very limited to log and to classes like the RunningContext which has the culture, current user id and the current datetime. This is a crucial decision that I would repeat on every system if I can. I can now debug easily by adjusting the time which is a major element in a stock system where orders, transactions and prices fluctuate in time.
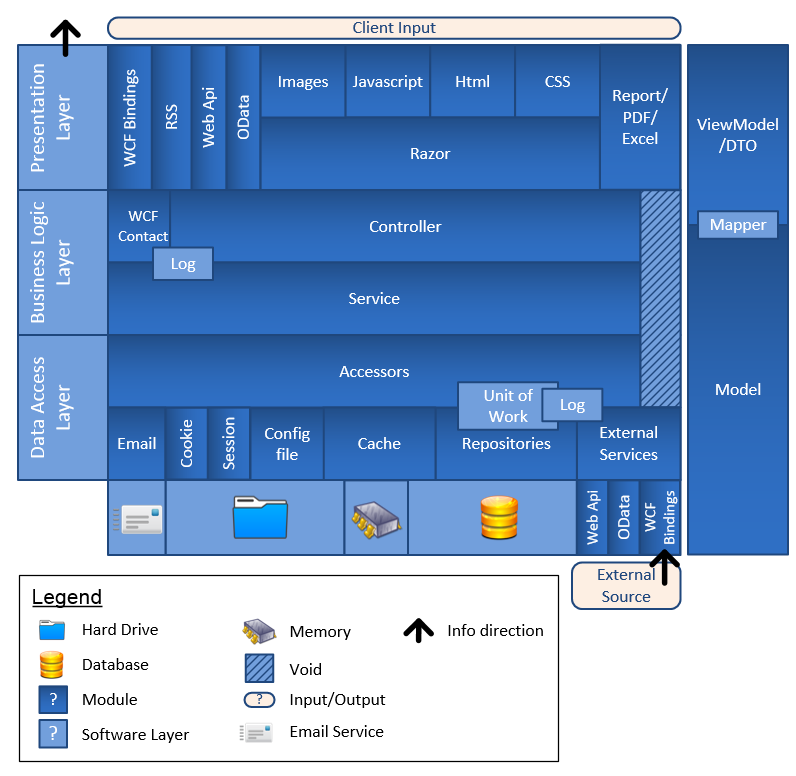
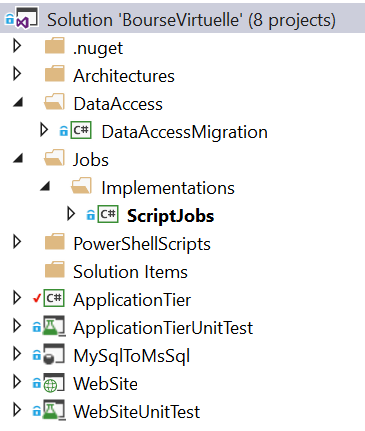
I started having all the layers and modules in different project. The solution had about 50 projects. For performance reason, I finished with 5 projects. The screenshot shows 8 buts one is the architecture models and one is the Mysql connector that was used during the migration and one is the Migration itself. Both of them are usually unloaded, hence 5 real projects.
I didn't loose any time in the architecture. Of course, the first sprint was more about planning with VSTS, creating some Visio document with classes, etc. But it was worth it. First of all, the work items got used. I didn't had all of them the first month, but most of them. The UML Visio diagrams was quite accurate to be honest. Of course, it misses about 50% of the classes since I involved and added more details. It misses them because they were not core classes and because I never took the time to updated it. During the development, I updated the architecture diagram that Visual Studio can produce in its Enterprise edition.
Open sourcing code
At some point, I decided to open sourced some codes of my application to be able to reuse it on others projects as well to share. In the following trend graph, we can see two drop of lines of code that result to that extraction of code outside the project. From this project, I have now :
So while the project has over 44 000 lines of code and comments, the real amount of code produced is approaching 50 000 lines of code. The idea of open sourcing code was good, but it added more overhead. First of all, extracting the code from the solution. Even if the code was well separated, logging and namespacing needed to change. Creating the Github repository, the Nuget package, the unit tests in xUnit instead of VsTest (which were not supported by Travis-ci) added some nights of work. Furthermore, debugging became harder too. From just adding a breakpoint in the code to having to reference the project and remove the Nuget, etc. For sure, it wasn't helping to get faster. That said, I am glad because these extracted library are well contained and tested.
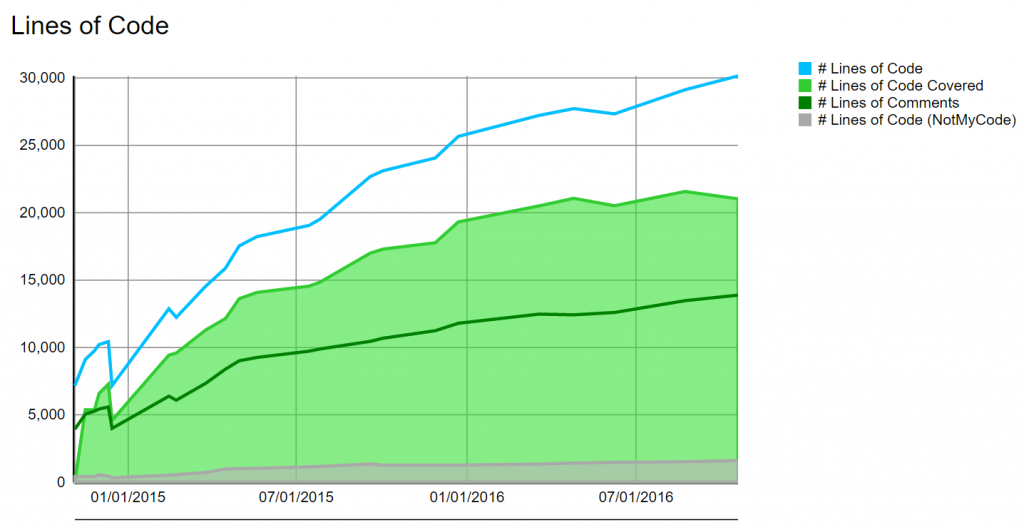
Some time was lost but most of the work was done inside the main project, hence the debugging was not intensive. I would say that I lost maybe 3 weeks (25-30 hours).
Tests
I am a big fan of automated tests. Even more if it's a single man project that I will be the one to maintain. I started doing my tests almost at the same time of my code, but after few months (around 6th-7th) was doing my test just before commiting, as a way to make sure that what I did was right and a validation that my code was well encapsulated with unique purpose. There is definitely benefits. On the 1800 automated tests, 1300 are unit tests and 500 are integration tests. By unit tests I mean very fast test that test methods without any dependencies -- everything is mocked. By integration tests, I mean test that use database, they integrate many pieces of the puzzle.
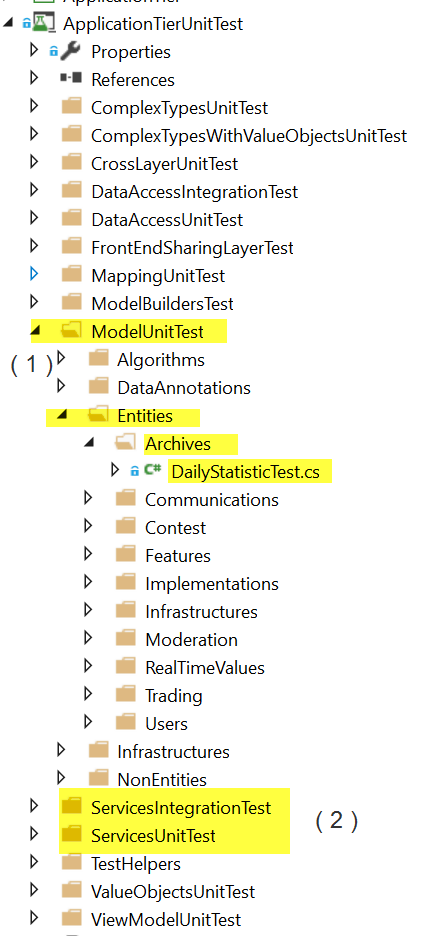
Unit tests
One problem I had and have is that I am still having some bugs that I shouldn't with my coverage of 70%. The problem I have an still have is that I have a lot of expected exceptions that are thrown and tested but the code that use those methods doesn't handle those exceptions. That is totally my fault and I need to work on that. Why I didn't do it is mostly because I know these cases shouldn't happen, but they do, sometime. Those edge cases need user experiences that are not defined. The reason I didn't do it was that I was short on my work item schedule or even was already late. Not a good excuse, but still the reality.
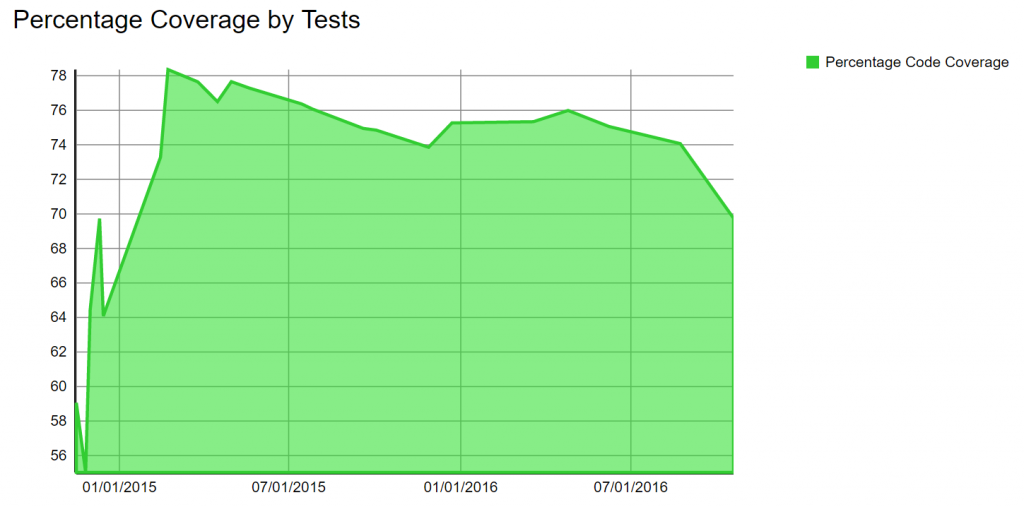
If you look at the trend graph, you can see that around march 2015 (sprint 14) the coverage fell from 78% to now 70%. I can blame no one else than myself. That said, I was reaching little down in motivation (my first and only one among the first 30 months) by seeing that I was not even half way through that project, I just had a new baby and was working a lot of hours at Microsoft. I cheated on the unit tests instead of cutting features. I definitely plan to increase them slowly. The major area where unit tests are missing at this point is the all controllers and few repository classes. The choice was deliberated to focus on the services and models classes which hold the core of the logic and are more incline to fail.
Integration tests
Integration tests started to be a way to have a persistence experience covered without having to do heavy testing with framework that click the UI. To cut the work and scope down, since we have unit tests, the only integration tests that was done was about the repository layer. The idea is good, but it was still time consuming. I have two formats for those code which rely on the same architecture : the tests initialize by creating a transaction and rollback the transaction once the test is done. The difference from the older version and the newest version is that the older one has a lot of utility methods to arrange the code. For example, "CreateUserThatHasNotValidatedEmail". The second one is using a Builder model with a fluent syntax. For example, I could do :
var data = this.DatabaseModelBuilder
.InsertNewUser(1, (applicationUser, index) => {
applicationUser.CanReceiveEmailWhenContestInscriptionStart = true;
applicationUser.ValidationDateTime = null;
});
Or more complex:
var s = this.DatabaseModelBuilder
.InsertNewFullContest()
.InsertNewPortefolio()
.InsertSymbolToRenameRequest()
.InsertSymbolToRenameVote()
.InsertStockTransactionInPortefolios(symbols);
While these examples may look just "okay" they are replacing a huge amount of work. Each of these methods are not just building the object but save them in the database, recuperate the generated ID, do associations, etc. This allowed me to avoid having hundreds of utility method for every cases but having a syntax that is reusable and can built-up. It also allowed to have cleaner methods.
Here is a shameful real code of the old way :
[TestMethod]
public void GivenBatchSymbolsRenameInOrders_WhenListHasStockToBeRenamed_ThenOnlySpecificStocksAreRenamed() {
// Arrange var uow = base.GetNewUnitOfWorkDapper();
var userId = this.runningContext.Object.GetUserId();
var repositoryExecuteContest = new ContestRepository(unitOfWorkForInsertion, uow, base.runningContext.Object);
var repositoryExecuteModeration = new ModerationRepository(unitOfWorkForInsertion, base.GetNewUnitOfWorkDapper(), base.runningContext.Object);
var repositoryUpdating = new OrderRepository(unitOfWorkForUpdate, base.GetNewUnitOfWorkDapper(), base.runningContext.Object);
var repositoryReading = new OrderRepository(unitOfWorkForReading, base.GetNewUnitOfWorkDapper(), base.runningContext.Object);
var date = this.runningContext.Object.GetCurrentTime();
var stock1 = new StockOrder { StockSymbol = new Symbol("msft"), Quantity = 100, TransactionTypeId = TransactionType.Buy.Id, OrderStatusId = OrderStatusType.Waiting.Id, OrderTypeId = OrderType.Market.Id, PlacedOrderTime = date, ExpirationOrderTime = date, UserWhoPlacedTheOrderId = userId.ToString()};
var stock2 = new StockOrder { StockSymbol = new Symbol("msft2"), Quantity = 100, TransactionTypeId = TransactionType.Buy.Id, OrderStatusId = OrderStatusType.Waiting.Id, OrderTypeId = OrderType.Market.Id, PlacedOrderTime = date, ExpirationOrderTime = date, UserWhoPlacedTheOrderId = userId.ToString() };
var stock3 = new StockOrder { StockSymbol = new Symbol("msft3"), Quantity = 100, TransactionTypeId = TransactionType.Buy.Id, OrderStatusId = OrderStatusType.Waiting.Id, OrderTypeId = OrderType.Market.Id, PlacedOrderTime = date, ExpirationOrderTime = date, UserWhoPlacedTheOrderId = userId.ToString() };
var stock4 = new StockOrder { StockSymbol = new Symbol("msft"), Quantity = 100, TransactionTypeId = TransactionType.Buy.Id, OrderStatusId = OrderStatusType.Waiting.Id, OrderTypeId = OrderType.Market.Id, PlacedOrderTime = date.AddDays(1), ExpirationOrderTime = date, UserWhoPlacedTheOrderId = userId.ToString() };
var symbolToRename = new SymbolToRename { CurrentSymbol = new Symbol("msft") ,EffectiveDate = date ,SymbolAfterRename = new Symbol("goog") ,UserWhoPlacedTheChangeId = this.runningContext.Object.GetUserId().ToString() ,Link = "http://" ,DateTimeChangePlaced = date
};
var vote = SymbolToRenameVote.Create(symbolToRename, new ApplicationUser() {
Id = this.runningContext.Object.GetUserId().ToString() }, 1, base.runningContext.Object); vote.Point = 100; vote.VoteDateTime = date;
// Arrange - Create Contest
var contest = contestModelBuilder.GetAStockContest();
repositoryExecuteContest.Save(contest); uow.Commit();
// Arrange - Create Request to change Symbol
symbolToRename = repositoryExecuteModeration.Save(symbolToRename); unitOfWorkForInsertion.Commit();
// Arrange - Create Vote
vote.SymbolToRename = symbolToRename; vote.SymbolToRename = null; vote.UserWhoVoted = null;
unitOfWorkForInsertion.Entry(vote).State = EntityState.Added; unitOfWorkForInsertion.Commit();
// Arrange - Create Portefolio
var portefolio = repositoryExecuteContest.SaveUserToContest(contest, userId); unitOfWorkForInsertion.Commit(); var portefolioId = portefolio.Id;
// Arrange - Create Stocks for Order
stock1.PortefolioId = portefolioId;
stock2.PortefolioId = portefolioId;
stock3.PortefolioId = portefolioId;
stock4.PortefolioId = portefolioId;
unitOfWorkForInsertion.Entry(stock1).State = EntityState.Added;
unitOfWorkForInsertion.Entry(stock2).State = EntityState.Added;
unitOfWorkForInsertion.Entry(stock3).State = EntityState.Added;
unitOfWorkForInsertion.Entry(stock4).State = EntityState.Added;
unitOfWorkForInsertion.Commit();
// Act
repositoryUpdating.BatchSymbolsRenameInOrders(symbolToRename);
unitOfWorkForUpdate.Commit();
// Assert
var stocks = repositoryReading.GetUserOrders(userId).ToList();
Assert.IsTrue(stocks.Any(d => d.StockSymbol.Value == "goog"), "goog symbol should be present in the portefolio");
Assert.AreEqual(1, stocks.Count(d => d.StockSymbol.Value == "msft"), "msft symbol should be present once in the portefolio");
}
A similar test with the new version:
[TestMethod]
public void GivenAListOfStocks_WhenRequestFirstPageAndThisOneHasLessThanTheFixedPageAmount_ThenReturnLessThanTheFixedAmountOfContests() {
// Arrange
const int ACTIVE_ORDER = 2; const int INACTIVE_ORDER = 2; const int PAGE_NUMBER = 0; const int NUMBER_CONTEST_PER_PAGE = 10; var allDatabaseOrders = new List<StockOrder>();
var data = this.DatabaseModelBuilder
.InsertNewFullContest()
.InsertNewPortefolio()
.InsertNewOrders(ACTIVE_ORDER, PREFIX_ACTIVE, true, order => { allDatabaseOrders = order.ToList(); })
.InsertNewOrders(INACTIVE_ORDER, PREFIX_INACTIVE, false, null);
var theNewestContestIs = data.GetallStockOrders().First();
// Act
var orders = data.GetStockOrdersByFilter(PAGE_NUMBER, NUMBER_CONTEST_PER_PAGE);
// Assert
Assert.AreEqual(ACTIVE_ORDER + INACTIVE_ORDER, orders.Count());
Assert.AreEqual(theNewestContestIs.Id, orders.First().Id);
}
Overall, the problem is the time it took to create a new integration test. The average was 20 minutes. With the new builder system, it's a little bit faster, because of the reusability, around 10 minutes if the builder miss some methods and under 5 minutes when the builder contains what it needs. It is always a little bit expensive because of the need to create code to prepare scenarios. I also had a lot of problem with Entity Framework because of the context which had previous data. If you want to arrange your test, you need different context that the one executing the code and the one asserting. Otherwise, you have some values in Entity Framework's context that interfere the reality of real scenario where data is inserted in different request. Another problem with Entity Framework was that the order of command was different from the code inside the repository which could change how some path was setting values inside Entity Framework. Result could be from DbConcurrency problem or from simply having association problem. I remember that I some point I was taking more time building those integration tests than doing the actual code.
My conclusion about integration tests is that they are required. Database can be tricky and it was beneficial to have an insurance that some automated tests was ensuring that values desired to be saved and retrieved was in the state expected. What I would change is, again, stop using Entity Framework. An additional reason why Entity Framework was causing more pain in integration test is that the invocation order for preparing the test wasn't the same as the service layer who invoked the code in test. For example, inserting a user, joining a simulation, creating an order is usually done by different requests, different Entity Framework context and with some logic in the services layer that we skipped in the integration test just to insert the data required. It would have been way easier just to do insert in the database for preparing the test with Raw SQL and then using the repository to read it. I also am sure that I do not need test with a framework that click around the UI. It was planned, but even if the UI is very stable, that would have add an additional layer of tests that is not essential, and very fragile and time consuming.
Front-end
Front-end had a radical shift around sprint 25ish. Mostly because performance metrics started to get in -- it was slow. I was using all capabilities available with some UIHint, auto detection from type with DisplayTemplates and EditorTemplates. Even with all performance tricks, it was slow. Razor is just not enough polish, and will never be. The new way of handling everything in JavaScript is where all the effort are at, and that is fine. That said, I could mitigate the problem by using Html helpers instead of templates. While that was quite few changes everywhere, it wasn't that long to do. I cannot say that it was a cause of I slip in the schedule, but as you can start to see, many 1-2 weeks unplanned items are getting added. You can clearly see that after 6-8 times you are already 3-4 months late.
JavaScript and CSS
I have 1 JavaScript and 1 CSS per view (page). Additionally, 1 JavaScript for the whole site, 1 css for the whole site. Everything is using Asp.Net Bundles so when in production, there is not big hit. I am not using any AMD loader because I do not need to -- the code is simple. It does simple tasks, simple actions and that's it. It modify the active view with JQuery and that's it. The CSS is also very simple, and I am leveraging Bootstrap to reduce a lot of complexity and having the UI responsive from cellphone to website. In my day to day job, I am using TypeScript, with modules, and React. I think this is the future, but it adds a lot of complexity and performance aren't that better. Having the server generating the UI might not be the current trend, but Razor aside I can generate the whole UI within few millisecond (mostly under 50ms). Slower than when it was in PHP, but still faster than a lot of UI I see these days. That said, I really like React and those big front-end framework, I just believe that if you have a website under 20 pages, that is not a single page application with simple UI that you do not need to go in the "trendy way" of Angular/React/VuesJs. I also believe that if you have an intranet website that you should avoid those big frameworks. That said, it's an other subject.
Entity Framework
I do not recommend Entity Framework. The initial version with .EDMX was bad, and I went straight away with Code First. But, the problem is deeper than that. First of all, there is about hundred of way to fail and configure your entities. Way to flexible, this best is hard to handle. While my configuration is quite well divided in configuration's classes, I had few hiccup in the first sprints. Like anyone I know who worked with Entity Framework's migration tool (to generate new setup code when your entities and configurations change) generation work well until it doesn't and you need to regenerate from scratch. Not that it's hard, but you are losing your migration's steps. Also, harder scenario are just not cover by the tool. For example, if you want to apply it on existing database with data. The biggest issue was about how Entity Framework's context is working with reference. You may load and want to save a new entity and Entity Framework will tell you that you have some DbConcurrency because entity has changed or that some association cannot be saved even if you ignored them, etc. All that pain comes also with bad performance. While it wasn't the worst part, it wasn't a nice cherry on top of it. I really wasted more than 120 hours (2 months) with problems here and there spread during these 30 months.
Migration from old to new
Migrating the data took me about 2 month of work. It was done in two times, one around the middle where I was thinking to migrate, and one 1 month before the actual release. Steps was to dump the MySql locally, uses an unstable primitive tool called Microsoft SQL Server Migration Assistant for MySQL. I qualify it of unstable because I had to change in Task Manager > Details tab > SSMAforMySql.exe > Context menu > Set Affinity > Core 0 only to be checked otherwise it was crashing. I also had to do it a lot of time to have all the data transferred. The migration didn't stop there. Once having the same schema from MySql in MsSql, I had to use C# project to push some C# code in the new database to be able to use the same algorithm that Asp.Net MVC do to hash password. The last and longer step was to create SQL script to transfer the database from the old legacy schema into the new one. The script takes more than 10 hours to run. There is millions and millions of data to be inserted.
I do not see how I could have those the migration faster than that. I had some waste of time with the tooling, but nothing dramatic.
Routing and Localization
The routing is exactly like I wanted which mean I do not have the culture in the URL. The system figures out with the string if the culture is between French or English. This is one of the open sourced project that is in GitHub now. I support two languages and I am using Microsoft's resource file. I have multiples resources files in different folders. I divided them by theme, for example "Exceptions.resx", "UI.resx", "DataAnnotation.resx", "HelpMessage.resx", "ValidationMessage.resx", "HomePage.resx", etc. I have about 40 resources files. That said, while it is not a waste of time I could say that having less files would be better. Now, I need someone to do some correction on those files and having to handle that many files is just not simple. The counter part is that these files do not have thousand of string each.
Performance
I got a huge surprise here. From my experience, developing with the PHP/MySql stack and publishing in a production server was always increasing the speed. For example, locally I could have a full rendering at 400ms locally, in production it would be 300ms. With Azure, it's not everything on a fast server but everything in the same data center. The first time I published the performance was the other way around. It comes from 400ms to 5 sec! I am not even exaggerating here. Without Redis, the performance is super bad. That said, I was using MemCached in the legacy system. Without the database I could have on heavy pages performance around 400ms-800ms, with Memcached on around 150ms-200ms. With all the performance improvements I did I am able to have page loading between 400ms to 2000ms for heavy huge page. It is still way slower (about 5x) than the legacy system. The problem is that calling Redis which is not on the same machine of the webserver add around 75ms per call. If you have to get 5 times data it adds there 300ms. If the cache is not hydrated, it adds even more with Sql Server. I did a lot of optimization to reduce the amount of call to Redis as well to have over 20 webjobs running in the background to hydrate Redis and did a lot of work to reduce payload between the webserver and Redis. It was fun to tweak the performance, but a whole sprint was dedicated to the issue. Performance is a never ending work and I think the time taken was required to have a usable system. I do not see a waste here but a reason of why a whole month was added to the schedule.
Azure
As we saw in the previous performance section, Azure was adding with the performance a whole month of work. However, performance wasn't the only problem. Azure configurations with VSTS for continue integration took me 2 nights. I started by going inside VSTS to have a new build step to push the built code in Azure but never succeed. After trying for 1 hours, I decided to move to Azure which can hook on VSTS's repository to do the build. That is a little bit the reverse of what I would naturally do but it works. It took me 20 minutes and I was up and running. Some works need to be done on VSTS side because it would be better to have VSTS push to Azure's slot since you can have VSTS runs your unit tests as a prerequisite before doing any other step.
Using LetsEncrypt 1 more night (it's not a single checkbox...), configuring Azure's slots and having to create Redis, delete Redis, etc few nights (you cannot just flush the Redis, you need to delete the instance and it takes a lot of time). I also had to send the database, configure the DNS (which is more complex than Cpanel), etc. Jobs was also difficult because there are so many way to do it. I started with Visual Studio's UI where you can setup with a calendar when each task start, but I needed a cronjob styles of syntax. I tried 2 different ways, the last one worked but still had some issues, needed to create an issue on GitHub, etc. Overall, having everything up and running took me about 3 weeks. I though it would take me 1 week. Overall, I think Azure or any other cloud service is great but most website can handle it with a single VPS or server for way less. I can configure Redis was faster than Azure do without having to pay the enormous monthly cost. For a corporation, the cost is justified since you might cut on IT resource. However, for small side-project that has low budget (or almost not revenues after paying servers and other costs) it can squeeze you even more. Azure is also changing quite a lot in some area, and in other it's stale which you never know if what you are using will still be there in 5 years or you will be forced at some point to update SDK. In my legacy Linux VPS, I can have everything ran for a decade without having to worry about it -- it just works. Azure is great, I do not regret since I learned a lot, but I didn't fall in the happy-wagon of not seeing that it doesn't fit every scenario. I also miss the feature of being able to configure email like in CPanel with Linux. It was literally taking 2 minutes to create a new email's box. On a final side note, Application Insights Analytic is very great, but too limited with only 7 days of custom data retention.
UX - User Experience
My goal was to provide a more inline help experience. The legacy system had inline help for stock order creation and all pages had a link to a Wiki. A Wiki works only if you have a motivated and participating community that is also a little bit technical to understand what is a Wiki. I also had a PHPBB forum. That worked great because I was creating in the background a PHPBB account when the user were creating their account. In the new system, I wanted to remove the Wiki since I was the only one contributing to it (had over 50 pages) and it was also a source of a lot of hackers. I wanted to remove the PHPBB forum because I didn't want to migrate to a Windows's alternative, neither have the time to go read it. I decided to bring help with bubbles around every single page. So far, these help are not very used (I have some telemetry) and they are not used until the end of the steps too. I also got some feedback from users asking for better help. I will have to create some video explaining the features when the user is new to stock exchange and to the system. There is a steep curve for sure, but my initial assumption was wrong: inline page is not enough and people prefer video than text.
Authentication, Facebook and Twitter Login
The new system allows you to connect with a single Facebook or Twitter account. Asp.Net MVC has some templates about it but still isn't all perfect with some hiccup depending of which provider you use. Twitter was the simpler to integrate for example. That said, I do not see a lot of user using it so far (still just 3 months since released and most people have already their account). This might has been released too fast and could have been delayed to a later stage. However, it wasn't a job of more than 2 nights. I am still very happy with my email inscription which require just a single email. The legacy system was also very simple but was requiring a password. Now, it's really just an email.
The idea was to have the user as quick as possible in the system. An email is sent with a temporary password, that allow me to validate that it's a real user and thus remove the need of a Captcha that I used in the legacy system. I am using SendGrid to send email and I really like their interface where it tell you if the user has receive/open/click the email. I have a greater ratio of email delivered for people having Hotmail account so far which is great. Before, in the legacy system, I was using directly SMTP.
Mapping
I use AutoMapper to map classes between the Model layer and ViewModel. I still believe that it is required to have different classes for the front end and the backend. The reason is that you have so many scenarios where the user interface needs specific fields in specific format that it's way cleaner not to create property in your model classes. For sure, with Entity Framework that would have been unreasonable since we would need a lot of configuration to ignore fields. I saw other architecture with classes for Entity which mean you need to map ViewModel->Model->Entity but that is a lot of mapping. Easier for Entity Framework, harder for the time of development. So, I did the good move. The only bad thing I see is that AutoMapper was the more problematic Nuget package I had to update. Not sure what is going on with Nuget but even if some major version imply breaking changes, it should be that often in 30 months. That said, it's not a big deal too and I am not using the latest because I am doing some automation which is more advanced scenario to bring from the model classes the translated properties name as well as the exception message. For example, if the FirstName in User's class fail, I'll bring automatically the property name from the resource file and attach it to the view model as well as the view model property.
Inversion of control (IOC)
Everything is passing from the controller down to the repository by inversion of control. I have been doing that pattern since so many years and it is a success in all points. The reason is that it makes testing so easy. You can mock interfaces passed easily. I didn't wasted anytime since I already used Microsoft Unity few times before in big projects. While I have been witness of performance issue with controlled injection in some other projects, I didn't see anything wrong with this one. I have to say that I do not pass more than 10 interfaces per controller which is probably the reason why it's not that heavy. IOC also helped when a instance needed to be singleton across request like logging events but also when in production I needed to sent real email instead of writing the email in a local .html file in development. This can be done with a unity release file configured in the release version of the web.config
Stripe vs Paypal
I am selling privilege account since the legacy system which give more features for the user. This time, as well as privilege account, I am also selling private simulation (contest). Before, I was using Paypal. Now, I am using Stripe. Why? Paypal API changed during the last years and it wasn't a pleasure to work with. I also got some trouble and account frozen, etc. I am also not a fan of Paypal way to not innovate. Stripe was and is a breeze to work with. Their API is clean, easy to use and allow user to use credit card without having any account. The integration was a charm and it took less than 6 hours to have everything setup. Testing it is also very easy.
Conclusion
Lot of great things happened during this project. The user of VSTS was definitely a good idea. It was hosting my source code, doing my build and organizing what I needed to do. All these features for free. The use of C# was like always a delight. Asp.Net MVC was also a good choice. While Razor will never been what it should have been in term of performance, the syntax was a pleasure to work with. Three years ago, there was no way I would have started that project differently. Right now, if I had to redo it again, I would aim more for a Single Page Application (SPA) with TypeScript and the new Asp.Net Core as the backend (which just get released to be usable for more serious project). That said, I wouldn't redo that project, at least not for a new decade. Handling more than 50 tables, more than 988 classes, 95 interfaces, 5736 methods is a little bit too big to learn about technologies without finishing the project with already a lot of already out of date. While I really believe that a project need to be bigger than just a dozen of entities to feel the reality and not just an illusion of that frameworks and libraries can do, handling too much just create a burden. I still have a lot of good memory about MySql and PHP. PHP is not as pretty as C# but it was pretty quick. MySql was also very great and easy to work with. Sql Server is more robust and has more features but I am not using most of them. Concerning speed, I haven't see a huge different. One thing that worry me is to be lock down to Azure. I could move into a Asp.Net server, transform those webjobs into services and be on IIS, but at that point, I know that I can get better with a Linux, Apache server. The situation is changing with Asp.Net Core and will reduce that feeling since it would be possible to use any kind of server.
I still have few months to improve unit tests, work on some features that will use existing data on the database/entities and continue to work to make it easier for the users to use the feature. Using Application Insights is awesome for the following months. By summer, I'll be in maintenance mode with this project and move on something completely new.